En el ejemplo de la aseguradora hemos partido de información sobre los tomadores del seguro: edad, sexo, año en el que obtuvo el carné de conducir, la marca del coche, su potencia... información que podemos llevar a una tabla:
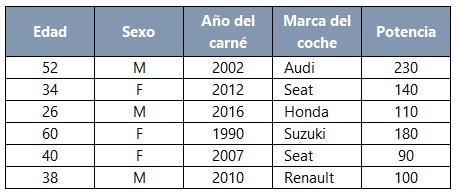
En esta tabla, cada columna recibe el nombre de atributo, campo, variable independiente, característica (feature en inglés) o característica predictiva (predictive feature). Obsérvese que esta información es en la que queremos basarnos para predecir si la persona de que se trate va a tener o no accidentes.
Por otro lado, cada fila de la tabla (correspondiente a una persona en nuestro ejemplo) recibe el nombre de muestra, instancia, instancia de entrenamiento (training instance), observación o registro. El nombre de muestra, aun siendo muy usado, puede resultar ambiguo pues, en estadística, una muestra es un subconjunto -normalmente aleatorio- de una población.
Esta tabla conteniendo las características predictivas será referenciada en nuestro código con la letra X (aplicando la convención habitual de dar a las matrices nombres de letras en mayúscula), y cada característica predictiva aparecerá referenciada en el texto del tutorial como xi, siendo i el índice o posición de la columna contando desde la izquierda. Así, en la tabla anterior, tendríamos cinco características predictivas a las que podríamos referirnos como x1 (la característica predictiva “Edad”), x2, x3, x4 y x5 (la característica predictiva “Potencia”).
Cuando sea necesario hacer referencia a una fila, usaremos la notación x(i), siendo i el índice o posición de la fila contando de arriba hacia abajo. De esta forma, en la tabla anterior tenemos seis filas a las que podríamos referirnos como x(1) (la situada en la parte superior), x(2), x(3), x(4), x(5) y x(6) (la situada en la parte inferior).
Combinando ambas notaciones, si quisiéramos hacer referencia al valor que una característica predictiva i toma en una fila j, escribiríamos xi(j).