sklearn.preprocessing.LabelEncoder()
La función sklearn.preprocessing.LabelEncoder codifica etiquetas de una característica categórica en valores numéricos entre 0 y el número de clases menos 1. Una vez instanciado, el método fit lo entrena (creando el mapeado entre las etiquetas y los números) y el método transform transforma las etiquetas que se incluyan como argumento en los números correspondientes. El método fit_transform realiza ambas acciones simultáneamente.
El único atributo de esta función, classes_, almacena el array que mapea etiquetas y números (que coinciden con el índice de cada etiqueta en el array).
Apliquemos esta función al dataset Titanic:
titanic = sns.load_dataset("titanic")
titanic.head(1)

En este dataset se incluyen varias características categóricas: sex, embarked, class... Vamos a aplicar el codificador a la característica "embark_town", por ejemplo. Comencemos confirmando los valores diferentes en este campo:
titanic.embark_town.unique()
Vemos que en el campo hay valores nulos que deberían ser tratados previamente. Como en este escenario el objetivo es probar el codificador LabelEncoder, vamos a optar por agrupar los valores nulos en una categoría independiente, dejando de lado opciones más sofisticadas como predicción vía Machine Learning:
titanic.embark_town.fillna("nan", inplace = True)
titanic.embark_town.unique()
Hemos convertido los valores nulos en etiquetas de texto con el valor "nan". Ahora ya podemos aplicar el codificador:
embark_town_codified = le.fit_transform(titanic.embark_town)
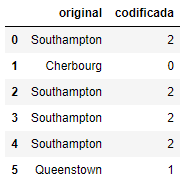
Veamos el mapa creado y comparemos los valores originales y las valores generados:
le.classes_
Este array nos indica que el valor "Cherbourg" va a ser mapeado al número 0, "Queenstown" al 1, etc.
pd.DataFrame({
"original": titanic.embark_town[:6],
"codificada": embark_town_codified[:6]
})
Ahora podríamos agregar los valores al dataframe o sustituir la columna original por el array que hemos creado. También podríamos hacerlo directamente:
titanic.embark_town = le.fit_transform(titanic.embark_town)
titanic.head()

Para terminar, el método inverse_transform permite transformar las etiquetas generadas en los valores originales.