En teoría, esta visualización es capaz de realizar análisis de clustering basándose en un enfoque de densidad (tipo DBSCAN). El panel de configuración es el siguiente:
Es decir, apenas dos campos que definen las coordenadas X e Y de los datos a analizar.
El problema de esta visualización es que, tras varias pruebas en las que se le han presentado datos del famoso dataset Iris, de "lunas" (producto de la función make_moons de sklearn) y de clusters producto de la función make_blobs de la misma librería, la respuesta de la visualización ha sido siempre la misma: "Could not get any cluster assigned as per the values as parameters". Por ejemplo, uno de los datasets utilizados ha sido el correspondiente al siguiente gráfico de dispersión:
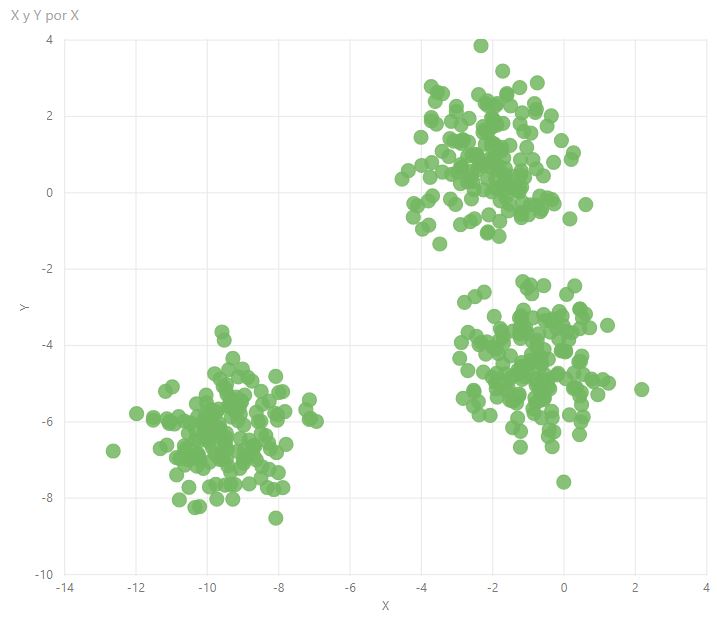
Parece difícil de entender que esta visualización no sea capaz de identificar los tres clusters...
Podríamos pensar que el problema está en la configuración de la visualización:

Vemos dos únicos campos: Parameter settings, que por defecto adopta una configuración automática, y Data scaling, que escala o no los datos. Si fijamos el valor User defined en el primero de estos dos campos se muestran tres campos personalizables:
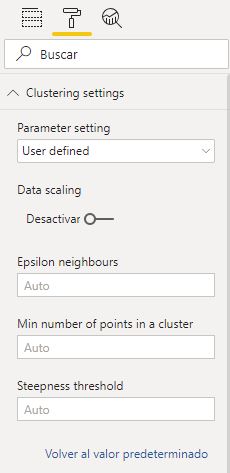
Epsilon neighbours que se corresponde con la distancia máxima entre puntos pertenecientes al mismo "vecindario", Min number of points in a cluster que, como bien indica su nombre, establece el número mínimo de puntos para crear un cluster, y Steepness threshold que, según el vídeo que acompaña a la visualización, tiene que ver con la gestión de clusters jerárquicos.
En cualquier caso, sea cual sea la configuración probada, el resultado de la visualización ha sido siempre el mismo:

Poco más se puede añadir. Decepcionante resultado, sin duda.