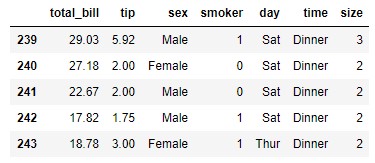
Librerías como Scikit-Learn o Pandas (por mencionar apenas un par de ellas) nos ofrece diferentes codificadores de características predictivas categóricas (LabelEncoder, OneHotEncoder, get_dummies, etc.), herramientas que nos devuelven los valores codificados, las etiquetas originales, el diccionario usado para la codificación, etc. Pero a veces nos encontraremos con la situación de querer codificar una característica predictiva a valores entre 0 y el número de clases -1, y no estamos interesados en ninguna otra funcionalidad. Por ejemplo, carguemos el dataset "tips" proveído por seaborn:
import seaborn as sns
data = sns.load_dataset("tips")
data.tail()
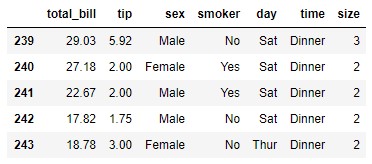
...y supongamos que queremos codificar la característica smoker a los valores 0 y 1 (y que no nos importa la asignación exacta que se realice). Este tipo de codificación "rápida y sucia" puede obtenerse con el siguiente código:
data.smoker.astype("category").cat.codes
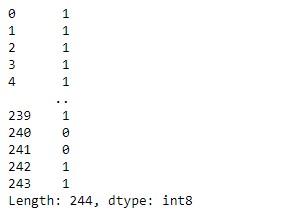
Comprobamos que, tras convertir el campo a tipo categórico y extraer los códigos, obtenemos un 1 para cada valor "No" de la característica predictiva y un 0 para los valores "Yes".
Si deseásemos sustituir la característica original por la versión codificada, bastaría con ejecutar el siguiente código:
data.smoker = data.smoker.astype("category").cat.codes
data.tail()