Podemos crear datos de entrenamiento y validación ficticios para entrenar una red neuronal para clasificación creada con Keras muy fácilmente. Debemos concretar:
- El número de muestras a generar para el conjunto de entrenamiento y para el conjunto de validación, que supondremos igual en este ejemplo.
- El número de características que tendrán ambos conjuntos.
- El número de clases a las que pertenecen las muestras generadas.
Comencemos importando las librerías involucradas:
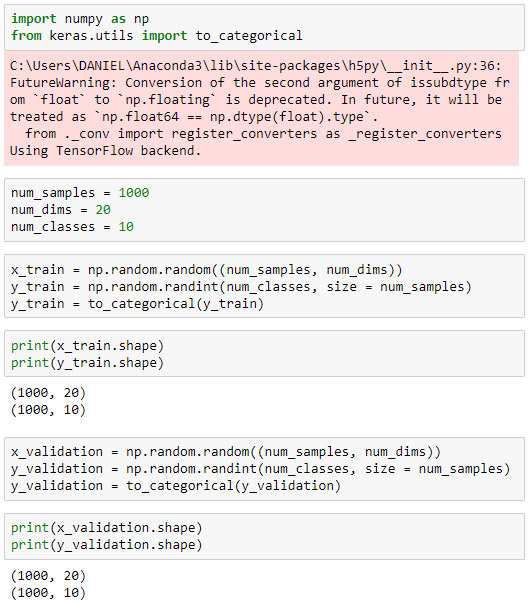
import numpy as np
from keras.utils import to_categorical
A continuación especifiquemos las variables mencionadas:
num_samples = 1000
num_dims = 20
num_classes = 10
Ahora ya podemos crear el conjunto de entrenamiento. Para generar las características usamos la función random de numpy especificando las dimensiones adecuadas (número de muestras y número de valores en cada una). Para generar las etiquetas usamos la función randint de numpy, para la que necesitamos especificar el valor máximo de los enteros a generar (hay que indicar un número más que el valor máximo pues también se generarán ceros. Es decir, para generar valores entre 0 y 7 incluidos, hay que especificar 8), y el número de muestras a generar (usando el parámetro "size"):
x_train = np.random.random((num_samples, num_dims))
y_train = np.random.randint(num_classes, size = num_samples)
El resultado devuelto por la segunda línea es un array numpy unidimensional, pero Keras necesita que este listado de etiquetas se codifique según la estrategia de "One Hot Encoding", y esta librería incluye una función para ello: to_categorical:
y_train = to_categorical(y_train)
Ahora y_train es un array numpy de dos dimensiones.
Para la generación del conjunto de validación podemos utilizar el mismo código:
x_validation = np.random.random((num_samples, num_dims))
y_validation = np.random.randint(num_classes, size = num_samples)
y_validation = to_categorical(y_validation)
Vemos a continuación el conjunto completo de instrucciones: