Probablemente, más significativo es el resultado dado por Random Forest, considerando que el entrenamiento de, por ejemplo, 500 árboles va a poner de manifiesto más claramente la mejora en el modelo provocada por cada característica.
Importamos, por lo tanto, la clase RandomForestClassifier:
E instanciamos el algoritmo, especificando una profundidad máxima de 3:
Validemos el modelo usando validación cruzada:
Se están clasificando correctamente el 98.4% de las muestras.
Ahora entrenamos el modelo:

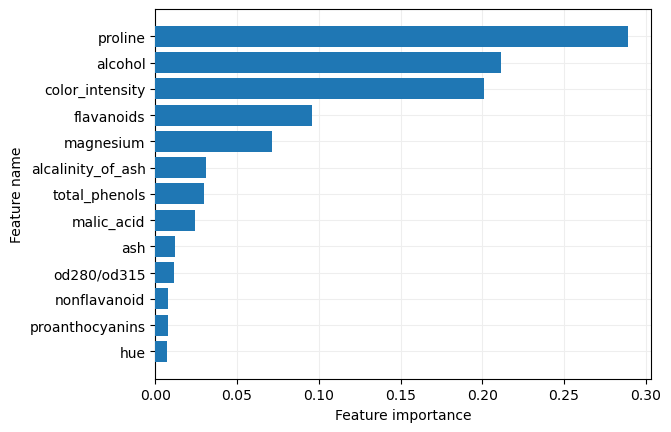
Comprobemos la importancia dada a cada característica:
importances
0.02969107, 0.09606957, 0.00769978, 0.00751063, 0.20109894,
0.00740945, 0.01171158, 0.28890394])
Mostremos esta información en una gráfica de barras:
sorted_importances = importances[indices]
sorted_feature_names = feature_names[indices]
ax.barh(y = sorted_feature_names, width = sorted_importances, zorder = 10)
ax.grid(color = "#EEEEEE", zorder = 0)
ax.set_xlabel("Feature importance")
ax.set_ylabel("Feature name")
plt.show()
Validemos el modelo si solo lo entrenásemos con las 5 características que mayor importancia han recibido:
Podríamos visualizar el porcentaje de aciertos considerando las n características con mayor importancia, haciendo variar n entre 1 y el número total de características, para lo que podemos entrenar 13 modelos y almacenar el porcentaje obtenido tras cada entrenamiento en la lista scores:
for num_features in range(1, len(X.columns) + 1):
score = cross_val_score(
model,
X[sorted_feature_names[-num_features:]],
y,
cv = 5
).mean()
scores.append(score)
Por último mostremos la evolución del "score" en función del número de características en una gráfica:
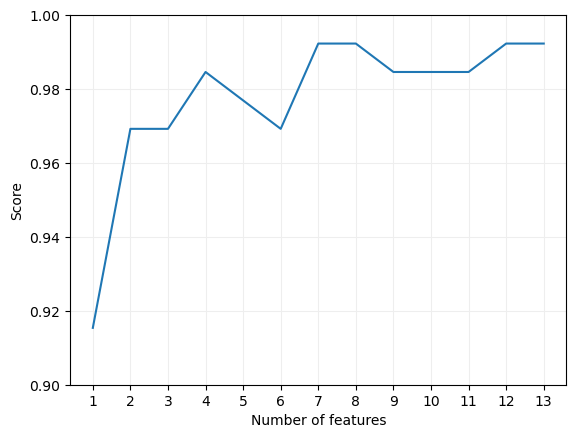
Comprobamos que se alcanza el máximo con 7 características.