En los ejemplos anteriores hemos fijado un umbral mínimo de la varianza por debajo del cual una característica predictiva se ignoraba. Pero podríamos también seleccionar las N características con mayor varianza. Para esto ni siquiera necesitamos la clase VarianceThreshold, basta con obtener las varianzas de cada característica ordenadas de mayor a menor, tal y como acabamos de hacer, seleccionar las N primeras y obtener sus índices. Por ejemplo, si N = 5:
features = X.var(ddof = 0).sort_values(ascending = False).iloc[:5].index
features
features
Index(['proline', 'magnesium', 'alcalinity_of_ash', 'color_intensity',
'alcohol'],
dtype='object')
'alcohol'],
dtype='object')
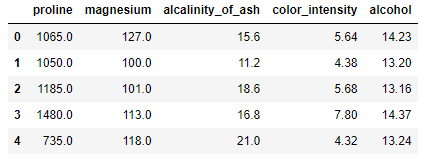
Ahora:
X[features].head()