Veamos un ejemplo en el que PCA (o LDA) no serían de utilidad: Scikit-Learn incluye la clase make_moons que permite generar puntos aleatorios con forma de dos lunas, puntos pertenecientes, por defecto, a dos clases::
from sklearn.datasets import make_moons
X, y = make_moons(random_state = 0)
X[:5]
array([[ 0.58322202, 0.75843021],
[ 1.71947411, -0.19596548],
[ 0.44507816, -0.23873905],
[ 1.51863492, -0.39084982],
[ 0.34573656, -0.21692838]])
[ 1.71947411, -0.19596548],
[ 0.44507816, -0.23873905],
[ 1.51863492, -0.39084982],
[ 0.34573656, -0.21692838]])
y[:5]
array([0, 1, 0, 1, 1], dtype=int64)
Mostremos estos datos gráficamente:
show_boundaries(None, X, None, y, None, np.unique(y))
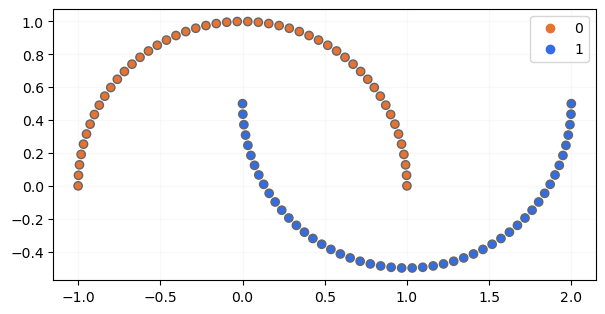
En este escenario, extraer el componente principal del dataset sería muy poco útil:
from sklearn.decomposition import PCA
pca = PCA(n_components = 1)
X_pca = pca.fit_transform(X)
X_pca = pca.fit_transform(X)
Mostremos los primeros cinco valores del resultado:
X_pca[:5]
array([[ 0.79597451],
[-1.26618544],
[-0.50553939],
[ 0.40741947],
[-0.73634878]])
[-1.26618544],
[-0.50553939],
[ 0.40741947],
[-0.73634878]])
Si queremos mostrarlos gráficamente, nuestra función show_boundaries requiere una estructura de dos dimensiones, de forma que añadamos una segunda columna con ceros:
X_pca2d = np.concatenate([
X_pca.reshape(-1, 1),
np.zeros(shape = (X_pca.shape[0], 1))
], axis = 1)
X_pca.reshape(-1, 1),
np.zeros(shape = (X_pca.shape[0], 1))
], axis = 1)
Ahora ya podemos visualizar los datos:
show_boundaries(None, X_pca2d, None, y, None, np.unique(y))

Los datos resultantes de aplicar PCA no permiten separar linealmente las dos clases.