Los árboles de decisión también pueden ser usados en análisis de regresión. El algoritmo aprende de los mismos bloques de características y etiquetas que, en este caso, son números. A la hora de realizar una predicción, se devuelve el valor medio de las etiquetas de las muestras en el nodo.
Scikit-Learn implementa este algoritmo en la clase sklearn.tree.DecisionTreeRegressor.
Veamos un ejemplo sencillo. Partimos de los siguientes datos aleatorios:
np.random.seed(0)
train = pd.DataFrame({
"x0": np.random.randint(1, 10, 25),
"x1": np.random.randint(1, 10, 25),
"y" : np.random.randint(1, 100, 25) * 10,
})
train.head()

Obsérvese que todas las etiquetas son valores múltiplos de 10.
test = pd.DataFrame({
"x0": np.random.randint(1, 10, 5),
"x1": np.random.randint(1, 10, 5)
})
test

y_train = train["y"]
X_train = train.drop("y", axis = 1)
X_test = test
Instanciamos el aprendiz y lo entrenamos estableciendo una profundidad máxima del árbol de 2:
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(random_state = 0, max_depth = 2)
model.fit(X_train, y_train)
Veamos el árbol creado:
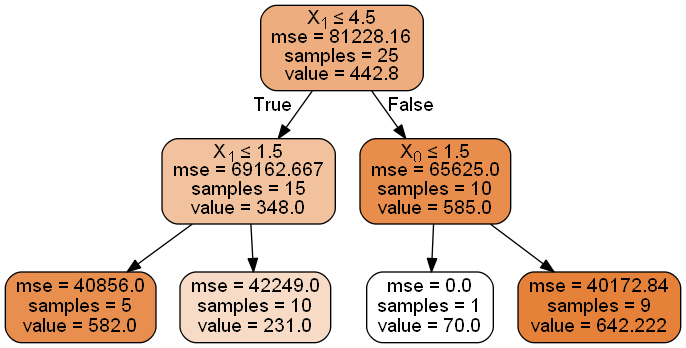
Comprobamos que el primer criterio de división (nodo raíz) es si la característica x1 toma un valor menor o igual a 4.5. En dicho nodo hay 25 muestras y el valor predicho (a devolver si este nodo fuese una hoja) es de 442.8, valor correspondiente a la media de las etiquetas:
train.y.mean()
442.8