
El dataset Boston está incluido en sklearn y ofrece valores medios de inmuebles en Boston a partir de características como la antigüedad del mismo, la tasa de criminalidad en la zona, etc.:
from sklearn.datasets import load_boston
dataset = load_boston()
dataset.keys()
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
La estructura devuelta por la instrucción anterior es un diccionario en el que los datos, la variable objetivo, los nombres de las características, la descripción del dataset y el fichero en el que está contenido se muestran en valores diferentes. Podemos crear un dataframe con las características y la variable objetivo de la siguiente forma:
boston = pd.DataFrame(dataset.data, columns = dataset.feature_names)
boston["target"] = dataset.target
boston.head()
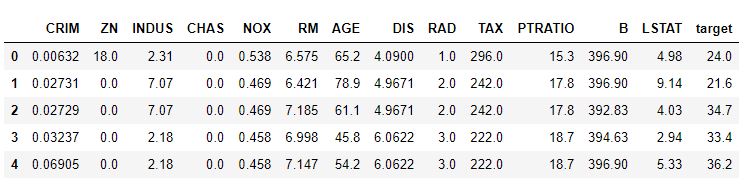
Como vemos, se trata de un dataset de 506 registros y 13 características predictivas (además de incluir la variable objetivo, por supuesto).