Para probar los histogramas de dos variables -también llamados histogramas bivariados- vamos a descargar un dataframe conteniendo información sobre propinas dejadas en un restaurante por los comensales. Este dataframe es proveído por la librería seaborn, de forma que comencemos cargando el dataset:
import seaborn as sns
tips = sns.load_dataset("tips")
tips.head()
De las características que ofrece vamos a trabajar con "total_bill" (coste total de la comida) y "tip" (propina dejada):
x = tips.total_bill
y = tips.tip
Echemos un vistazo a la distribución de estas características mostrando su diagrama de dispersión:
plt.scatter(x, y);
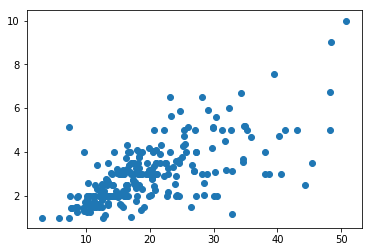
Podemos ver cómo la mayor parte de los puntos definidos por ambas características se concentran en el cuadrante inferior izquierda.
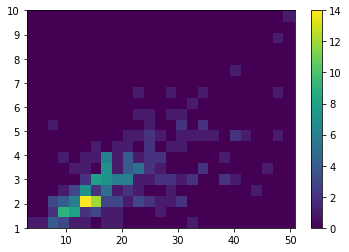
El histograma de dos variables, matplotlib.pyplot.hist2d, divide el plano en diferentes áreas rectangulares, y considera el número de puntos por área, mostrando cada una con un color diferente en función del número calculado:
plt.hist2d(x, y);
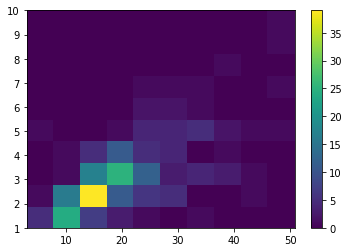
El área mostrada en amarillo es la correspondiente al área del diagrama de dispersión con mayor número de puntos. Es posible añadir una barra de colores que ayude a la interpretación utilizando la función matplotlib.pyplot.colorbar:
plt.hist2d(x, y);
plt.colorbar();
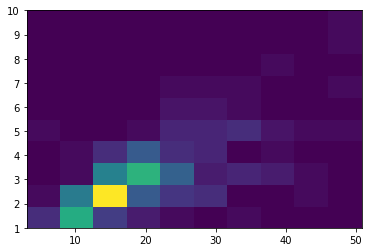
También es posible modificar el número de áreas en las que dividir el plano utilizando el parámetro bins. Si éste es un número, se dividirá tanto el eje x como el eje y en tantos bloque como indique. Si se trata de un array de dos elementos o estructura semejante, el primer número hará referencia al número de bloques en los que dividir el eje vertical, y el segundo al número de bloques en los que dividir el eje horizontal.
plt.hist2d(x, y, bins = (25, 20));
plt.colorbar();