Los gráficos de dispersión, también denominados diagramas de dispersión o scatter plots en la literatura en inglés, se utilizan para comparar los valores que toman dos variables distintas, una de las cuales se representa a lo largo del eje x y la otra a lo largo del eje y. La gráfica resultante nos permite identificar visualmente la posible correlación entre las dos variables.
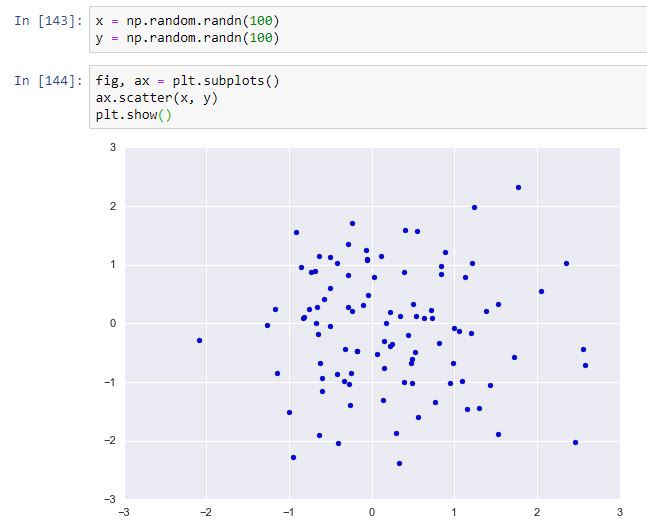
En mapplotlib, aun cuando es posible crear este tipo de gráficas con la ya conocida función plt.plot (basta ocultar las líneas y mostrar solo los puntos), existe una función mucho más potente: la función matplotlib.pyplot.scatter (funcionalidad también disponible como método de un conjunto de ejes). Esta función acepta como primeros dos argumentos los valores x e y de los puntos a mostrar. Hagamos un ejemplo sencillo: generemos valores aleatorios extraídos de una distribución normal para los valores de x y de y y crucémoslos en un gráfico de este tipo:
Más útil resulta este tipo de gráfica cuando estamos visualizando elementos de diferente clase y los mostramos en el gráfico con diferenes colores. Para probar esta función, vamos a trabajar con datos sencillos pero reales: el conjunto de datos Iris conteniendo el ancho y el largo de los pétalos y sépalos de 150 flores de tres especies de Iris (setosa, versicolor y virginica). Vamos a cargarlo en un dataframe pandas con el siguiente código:
data = pd.read_csv("https://interactivechaos.com/sites/default/files/data/iris_data_set.csv")
A continuación podemos confimar el tamaño de los datos leídos y visualizar las primeras filas:
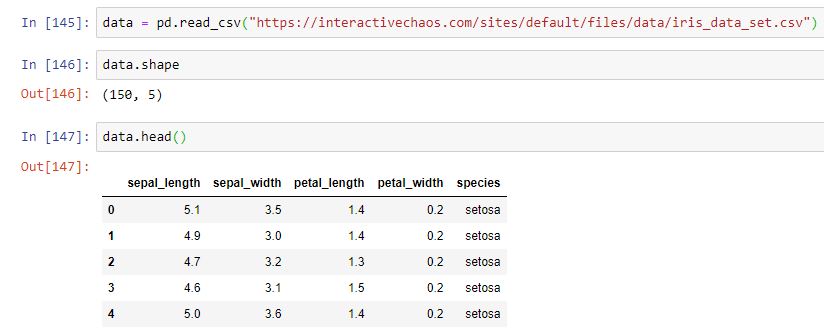
Confirmamos que se trata de 150 registros y que es en la última columna ("species") donde se almacena la especie de la flor.
Vamos a cruzar las variables "sepal_length" y "sepal_width", información que cargaremos en las variables x e y. Pero vamos a usar también el parámetro c de la función plt.scatter que permite indicar cuál es el color de cada uno de los puntos. Es decir, necesitamos una estructura tipo array de 150 elementos que indiquen el color de cada punto, color que representará la especie de cada muestra. Para ello, vamos a crear un diccionario que asocie cada tipo de especie con un color, y vamos a "mapear" la columna "species" con este diccionario:

Ahora ya podemos pasar a la función plt.scatter las dos primeras columnas del dataframe y la recién calculada estructura "species_color" (una serie pandas):
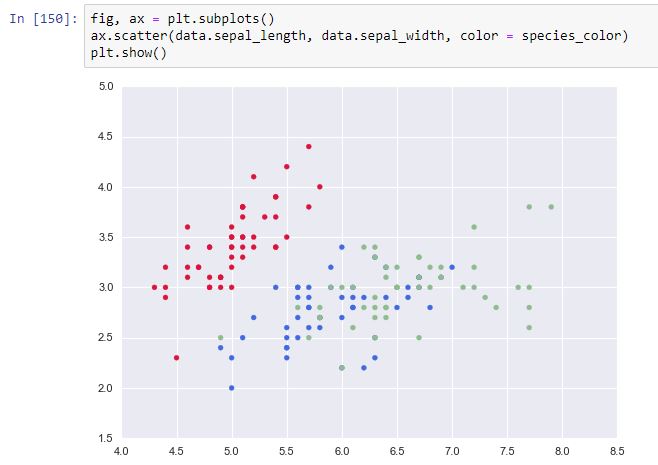
Es apreciable la distancia que separa el cluster representado por los puntos rojos (flores "setosa") de los otros dos que se muestran más mezclados.
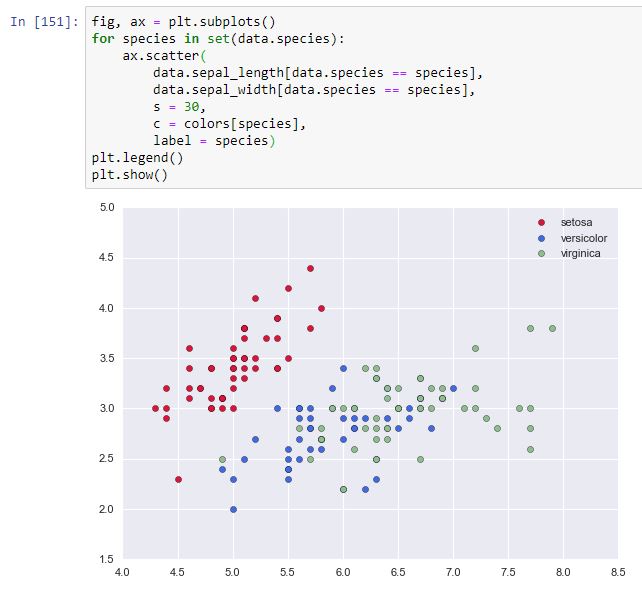
Si queremos añadir una leyenda nos encontramos con un pequeño problema pues, si recuerdas, la leyenda toma las etiquetas de las diferentes gráficas que se incluyesen en los ejes: si incluíamos tres gráficas (cada una con sus datos), asignábamos a cada una una etiqueta, y era esta etiqueta la mostrada en la leyenda. Esto, trasladado a nuestro ejemplo, significa que si quisiéramos que la leyenda distinguiera entre 'setosa', 'versicolor' y 'virginica', tendríamos que crear tres gráficos de dispersión, uno para cada tipo de flor, y dar a cada uno una etiqueta diferente. Y solo entonces podríamos mostrar la leyenda. Aun cuando resulta un poco más complejo de lo que cabría esperar, podemos hacerlo sin mayor problema. El código es el siguiente:
fig, ax = plt.subplots()
for species in set(data.species):
ax.scatter(
data.sepal_length[data.species == species],
data.sepal_width[data.species == species],
s = 30,
c = colors[species],
label = species)
plt.legend()
plt.show()
Como ves, tras crear la figura y el conjunto de ejes, recorremos en bucle los tipos de especies y, para cada uno, añadimos un diagrama de dispersión al que pasamos los datos del dataframe data que se corresponden solo con la especie que estemos considerando. El parámetro s controla el tamaño de los puntos, y seguimos asignando el mismo color que antes a cada especie (usando el mismo diccionario que teníamos). El resultado es el siguiente: