Supongamos que estamos trabajando con 3 muestras del conjunto de datos iris cuya especie querríamos predecir a partir de las cuatro características disponibles de las flores: longitud y ancho de pétalos, y longitud y ancho de sépalos (es decir, estamos trabajando en un espacio de 4 dimensiones). Comenzamos codificando las especies en valores numéricos:
iris = sns.load_dataset("iris")
le_iris = LabelEncoder()
iris["target"] = le_iris.fit(iris.species).transform(iris.species)
iris = iris.drop("species", axis = 1)
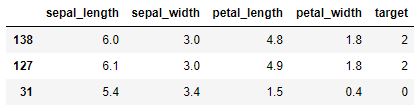
Extraemos en iris_test el conjunto de datos a predecir y dejamos en iris_train el resto de datos (que será el conjunto de entrenamiento)
iris_test = iris.sample(3, random_state = 1112)
iris_train = iris.drop(iris_test.index)
Separemos ahora estas estructuras en características predictivas y variable objetivo:
y_train = iris_train.pop("target")
X_train = iris_train
y_test = iris_test.pop("target")
X_test = iris_test
Creemos ahora un modelo basado en k-NN. Para ello vamos a utilizar la clase KNeighborsClassifier de la librería Scikit-learn especificando k = 1. Este algoritmos nos permite escoger 1) los pesos a aplicar a los vecinos (para que, por ejemplo, el voto de los vecinos más próximos tenga mayor peso), 2) el método a aplicar para calcular los k vecinos de cada punto y 3) la métrica de distancia a utilizar:
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors = 1)
Ahora podemos entrenar el algoritmo con el conjunto de datos de entrenamiento:
model.fit(X_train, y_train)

Vemos en el resumen que se muestra que la métrica que se utiliza por defecto es la distancia de Minkowski con p = 2, lo que equivale a la distancia Euclidea.
Realicemos la predicción para las tres muestras que habíamos extraído:
prediction = model.predict(X_test)
print(prediction)
le_iris.classes_[prediction]
[1 2 0]
array(['versicolor', 'virginica', 'setosa'], dtype=object)
Confirmemos el porcentaje de acierto que hemos obtenido:
model.score(X_test, y_test)
0.6666666666666666
El acierto ha sido del 66%. Repitamos el proceso con tres vecinos:
model = KNeighborsClassifier(n_neighbors = 3)
model.fit(X_train, y_train)
prediction = model.predict(X_test)
print(prediction)
le_iris.classes_[prediction]
[2 2 0]
array(['virginica', 'virginica', 'setosa'], dtype=object)
Y calculemos nuevamente el porcentaje de acierto con esta configuración: