La librería Scikit-Learn ofrece esta funcionalidad en la clase LinearDiscriminantAnalysis. Apliquémosla al dataset Wine. Carguemos los datos y escalémoslos:
from sklearn.datasets import load_wine
wine = load_wine()
data = pd.DataFrame(data = wine.data, columns = wine.feature_names)
data.rename({
"nonflavanoid_phenols": "nonflavanoid",
"od280/od315_of_diluted_wines": "od280/od315"
}, axis = 1, inplace = True)
data["label"] = wine.target
X = data.drop("label", axis = 1)
y = data.label
data = pd.DataFrame(data = wine.data, columns = wine.feature_names)
data.rename({
"nonflavanoid_phenols": "nonflavanoid",
"od280/od315_of_diluted_wines": "od280/od315"
}, axis = 1, inplace = True)
data["label"] = wine.target
X = data.drop("label", axis = 1)
y = data.label
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_scaled = scaler.fit_transform(X)
Ahora vamos a importar la clase LinearDiscriminantAnalysis e instanciarla. El número de componentes a extraer (el número de características) deberá ser menor que el número de clases a clasificar. En nuestro caso tenemos tres clases de vinos, por lo que el número de características no podrá ser mayor que 2. Si no especificamos ningún valor, será éste el número de características extraídas:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis()
Transformamos ahora los datos:
X_lda = lda.fit_transform(X_scaled, y)
X_lda.shape
(178, 2)
Comprobamos que, efectivamente, se han extraído dos características:
X_lda[:5]
array([[4.70024401, 1.97913835],
[4.30195811, 1.17041286],
[3.42071952, 1.42910139],
[4.20575366, 4.00287148],
[1.50998168, 0.4512239 ]])
[4.30195811, 1.17041286],
[3.42071952, 1.42910139],
[4.20575366, 4.00287148],
[1.50998168, 0.4512239 ]])
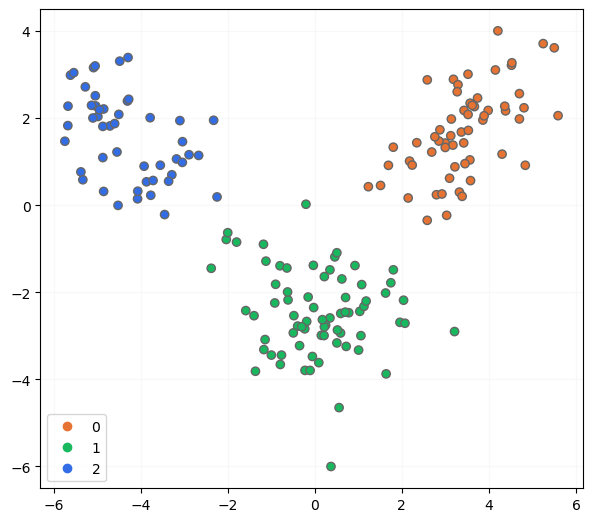
Visualicemos los nuevos datos:
show_boundaries(None, X_lda, None, y, None, y.unique())