El método descrito es el conocido como método de retención o holdout method. Por ejemplo, si estamos construyendo un modelo clasificador que sea capaz de clasificar bolas amarillas y verdes, y tenemos un conjunto de datos etiquetados (es decir, un conjunto de bolas amarillas y verdes acompañado de las etiquetas que indican el color de cada bola):

podríamos dedicar el 80% de los datos a entrenar el algoritmo y el 20% restante a validarlo:
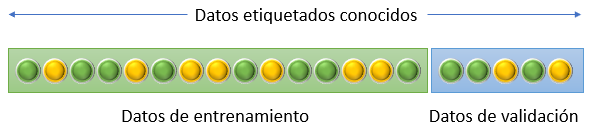
Los porcentajes frecuentemente usados en estos casos suelen ser 75/25, 80/20 o incluso 90/10, en función del número de datos con los que contemos. En un caso extremo, si contamos con, por ejemplo, un millón de muestras en el dataset de entrenamiento, podría ser suficiente con reservar apenas un 1% de ellas (10 mil muestras) para validación, y usar el 99% restante para entrenar el modelo.