Frecuentemente los datos que estamos analizando no tienen una distribución lineal. Por ejemplo:
np.random.seed(0)
X = 10 * np.random.rand(100, 1) - 5
y = 0.5 * X ** 2 + 1.5 * X + 3 + np.random.randn(m, 1)
fig = plt.figure(figsize = (8, 6))
sns.scatterplot(x = X.flatten(), y = y.flatten());
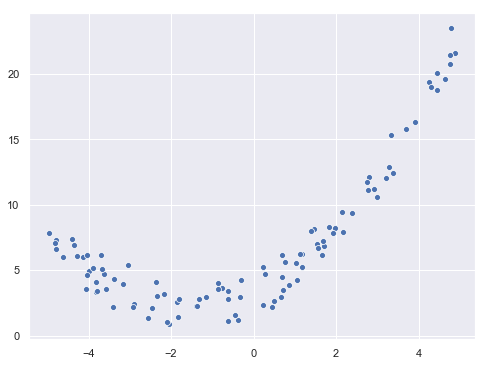
En un caso como este, intentar aproximarlos mediante una recta del tipo
...daría un pésimo resultado. Esto no significa, sin embargo, que no podamos usar un modelo lineal. Por el contrario, si la ecuación anterior tuviese, por ejemplo, la siguiente forma:
...resultaría mucho más sencillo poder captar las no linealidades del dataset. Esta conversión es posible utilizando la clase sklearn.preprocessing.PolynomialFeatures que, en su entrenamiento, recibe como entrada el conjunto de características predictivas y, al transformarlas, devuelve las posibles combinaciones entre ellas hasta el grado indicado al instanciar la clase. Por ejemplo, si el dataset de entrada tiene dos variables predictivas "a" y "b", y se instancia la clase PolynomialFeatures indicando como grado el valor 2, la transformación del dataset devolverá las (nuevas) características [1, a, b, a2, b2, ab] (6 características).