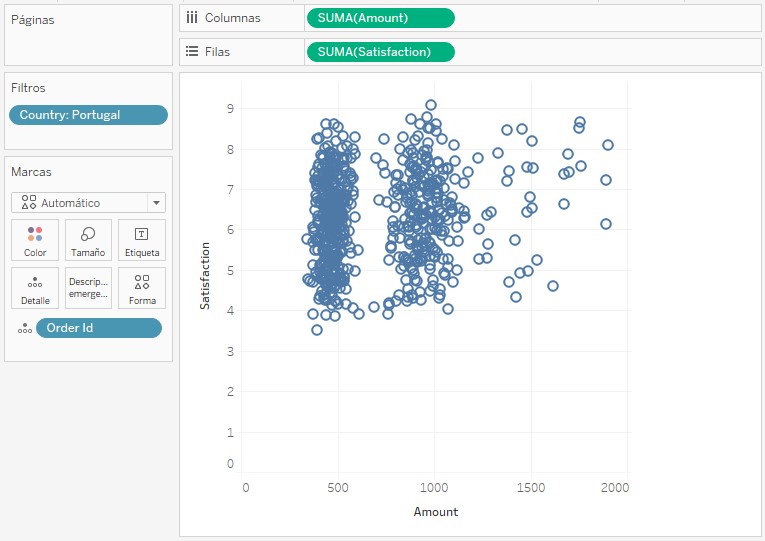
Esta herramienta permite identificar clústers (agrupaciones) en nuestros datos. Para probarla vamos a crear un diagrama de dispersión llevando el campo Satisfaction (satisfacción de cada cliente con su compra) al estante de filas, el campo Amount (precio de venta) al estante de columnas y el campo Order Id a la propiedad de Detalle para ver el desglose. Como son muchos puntos, limitemos el análisis a Portugal: llevemos el campo Country al estante de filtros y seleccionemos este país:
Ahora arrastremos el Clúster desde el panel de análisis hacia el lienzo. Solo se muestra un receptor:
Si soltamos el Clúster sobre él, se muestra una ventana donde vemos las variables y funciones de agregación consideradas (que podríamos modificar) y el número de clústers a crear. La opción por defecto es Automático, pero podemos escribir cualquier número entre 2 y 50 (el gráfico se actualiza aproximadamente un segundo después de que lo hayamos modificado):
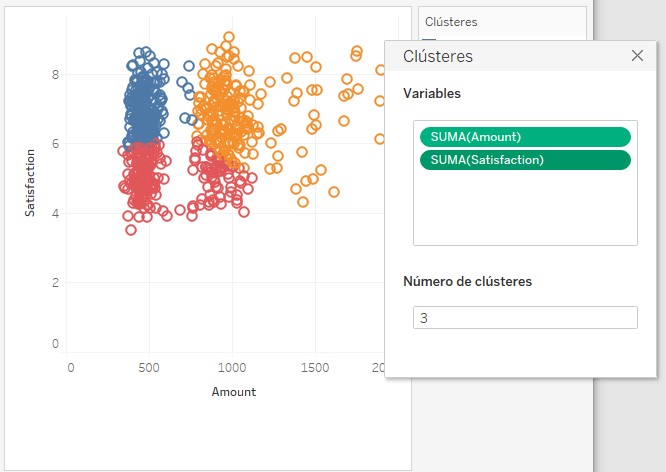
Desafortunadamente, ésta es toda la configuración que se nos ofrece. Podemos cerrar la ventana pulsando la tecla escape o haciendo clic en el aspa que se muestra en su esquina superior derecha.
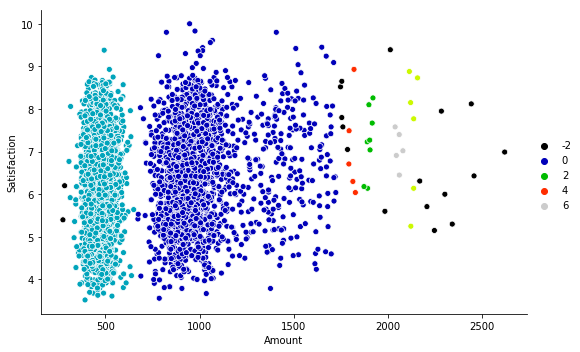
Vemos que los clústers son creados por un algoritmo K-Means (basado en distancia entre muestras), no tipo DBSCAN (basados en densidad de datos), lo que puede limitar su utilidad en ciertos escenarios. En todo caso, el resultado obtenido para este ejemplo es bastante pobre. Por ejemplo, la imagen siguiente muestra el resultado que se obtiene para los mismos datos aplicando el algoritmo K-Means en Python (no usando Tableau):
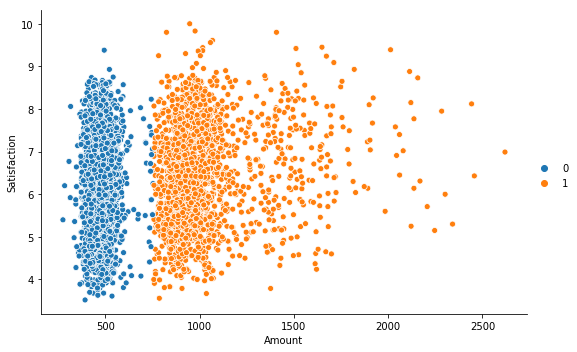
En este caso los clústers -incluso aplicando el criterio de distancia- son mucho más identificables.
Si aplicamos -también en Python-, un algoritmo basado en densidad como DBScan, el resultado es semejante, identificándose 6 clústers -al menos con la configuración usada-: