Una tabla dinámica (o pivot table en inglés) es una tabla que muestra información resumida extraída de otra tabla. Esta última es un listado de muestras (registros o puntos) con un cierto número de campos o características, por ejemplo:
df = pd.DataFrame({
'foo': ['one', 'one', 'one', 'two', 'two', 'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']
})
df
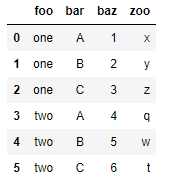
Una tabla dinámica va a agrupar información a partir de esta tabla de la siguiente forma:
- Va a seleccionar una (o más) características para ocupar el índice de filas, de forma que cada valor que tome dicha característica se muestre en una fila
- Va a seleccionar una (o más) características para ocupar el índice de columnas, de forma que cada valor que tome dicha característica se muestre en una columna
- Va a seleccionar una (o más) características para ocupar las intersecciones de filas y columnas
- Al conjunto de registros representados en cada una de esas intersecciones les va a aplicar una función de agregación, que puede ser tan simple como un recuento, cálculo del valor medio, etc.
El método pandas.DataFrame.pivot_table crea una tabla dinámica de esta forma a partir de un dataframe. Veamos varios ejemplos comenzando por los más simples:
En el dataframe visto comprobamos que la características foo toma dos posibles valores (one y two), y la característica bar toma tres (A, B y C). Podríamos mostrar la distribución de la variable baz respecto de foo y bar de la siguiente forma:
df.pivot_table(index = "foo", columns = "bar", values = "baz")

En este caso, los valores que toma la característica incluida en el parámetro index van a distribuirse a lo largo del eje vertical, y los valores que toma la característica incluida en el parámetro columns van a distribuirse a lo largo del eje horizontal. Los valores que toma la variable incluida en el parámetro values van a la intersección de filas y columnas, aplicándoseles una cierta función de agregación que, por defecto, es np.mean (cálculo del valor medio). El ejemplo mostrado es muy pequeño y para cada intersección de filas y columnas solo hay un registro, de forma que el valor medio del valor contenido en la columna baz de cada registro coincide con el mismo valor. Por ejemplo, la intersección de foo = one y bar = A representa un conjunto de registros del dataframe que, en nuestro caso, se limita a un único registro (el registro con índice 0) en el que el valor de baz es 1, y su valor medio es 1.
Podemos aplicar otra función de agregación utilizando el parámetro aggfunc:
df.pivot_table(index = "foo", columns = "bar", values = "baz", aggfunc = "count")

En este ejemplo hemos contado el número de registros representados en cada intersección.
Es posible aplicar más de una función de agregación a los datos. En el siguiente ejemplo aplicamos tanto la función de cálculo del valor medio como el recuento:
df.pivot_table(index = "foo", columns = "bar", values = "baz", aggfunc = [np.mean, "count"])
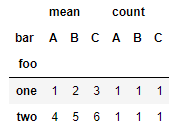
Como puede comprobarse, pandas crea un conjunto de columnas diferente para cada función de agregación.
Hagamos algunos ejemplos con un dataset un poco más rico en contenido, por ejemplo el dataset del Titanic:
titanic = sns.load_dataset("titanic")
titanic.head(2)

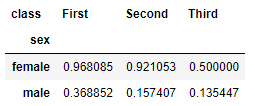
Mostremos el valor medio de la característica survived (es decir, el porcentaje de los que sobrevivieron) desglosando la tabla por sexo y clase:
titanic.pivot_table(index = "sex", columns = "class", values = "survived")
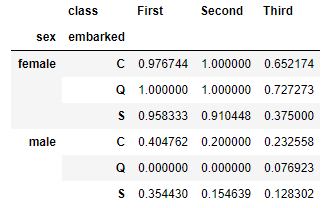
Si llevamos dos (o más) campos a index, los valores que tome el primero de ellos se desglosa a su vez según los valores que tome el segundo. Por ejemplo, podemos repetir el ejercicio anterior desglosando las filas por sexo y puerto de embarque:
titanic.pivot_table(index = ["sex", "embarked"], columns = "class", values = "survived")
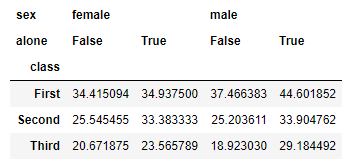
De forma semejante, si llevamos dos (o más) campos a columns, los valores que tome el primero de ellos se desglosa a su vez según los valores que tome el segundo. En el siguiente ejemplo queremos analizar el valor medio de la edad de los pasajeros por clase (en filas) y por sexo y si viajaba o no solo (por columnas):
titanic.pivot_table(index = "class", columns = ["sex", "alone"], values = "age")
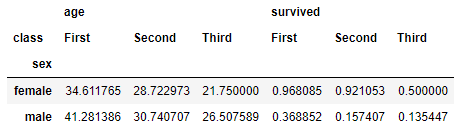
Por último, si llevamos dos (o más) campos a values, pandas va a crear un conjunto de columnas para cada uno de dichos campos:
titanic.pivot_table(index = "sex", columns = "class", values = ["survived", "age"])
Este método incluye también parámetros que permite rellenar los valores nulos (fill_value) y añadir subtotales de filas y columnas (margins).