Este método, llamado en inglés leave-one-out cross-validation, consiste en considerar como sub bloque de validación una única muestra, tomando el resto como sub bloque de entrenamiento, lo que obliga a entrenar tantos modelos como número de muestras existan.
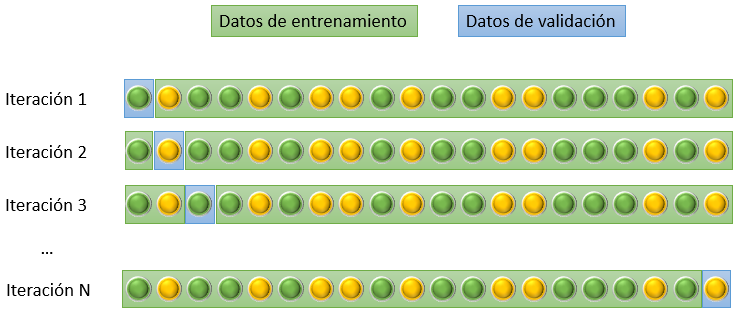
El resultado de este enfoque puede considerarse óptimo desde el punto de vista de su exactitud. Sin embargo, esto se consigue a costa de un aumento de la capacidad de computación necesaria para el entrenamiento de todos los modelos, aumento que generalmente no es asumible.
Scikit-Learn ofrece esta funcionalidad en la clase sklearn.model_selection.LeaveOneOut.