Una cosa importante que debemos resaltar: la expresión que incluyamos como segundo argumento de SUMX, AVERAGEX, etc. se va a evaluar en contexto de fila a medida que se recorre la tabla indicada como primer argumento. Pero esta tabla se evalúa en contexto de filtro antes de ser iterada (y esto es muy importante). Es decir, si tenemos la medida
AVERAGEX(
Sales,
Sales[Delivery Date] - Sales[Order Date]
)
la tabla Sales que se pasa a la función AVERAGEX como primer argumento se va a evaluar en contexto de filtro (lo que significa que, cuando se ejecute nuestra medida Avg Delivery Time, no todas sus filas estarán necesariamente visibles, pues pueden estar aplicándose filtros a nuestro modelo de datos) y, una vez identificadas qué filas quedan visibles en la tabla Sales, serán esas filas las que se recorran una por una evaluando la expresión de que se trate en contexto de fila.
Así, en el ejemplo visto en el que mostrábamos en una tabla los valores medios de entrega por país, fijémonos en el primer valor obtenido (el correspondiente a Francia):
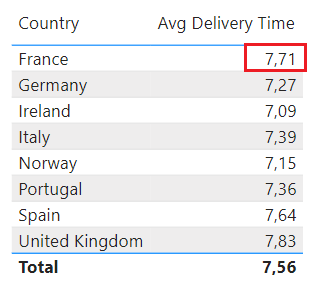
El contexto de filtro que rodea a ese cálculo es el correspondiente a tener todas las filas de todas las tablas visibles salvo en la tabla Geography, tabla en la que solo las filas en las que el campo Country toma el valor “France” están visibles, filtro que se propaga a la tabla de ventas de forma que solo las ventas asociadas a Francia están visibles:
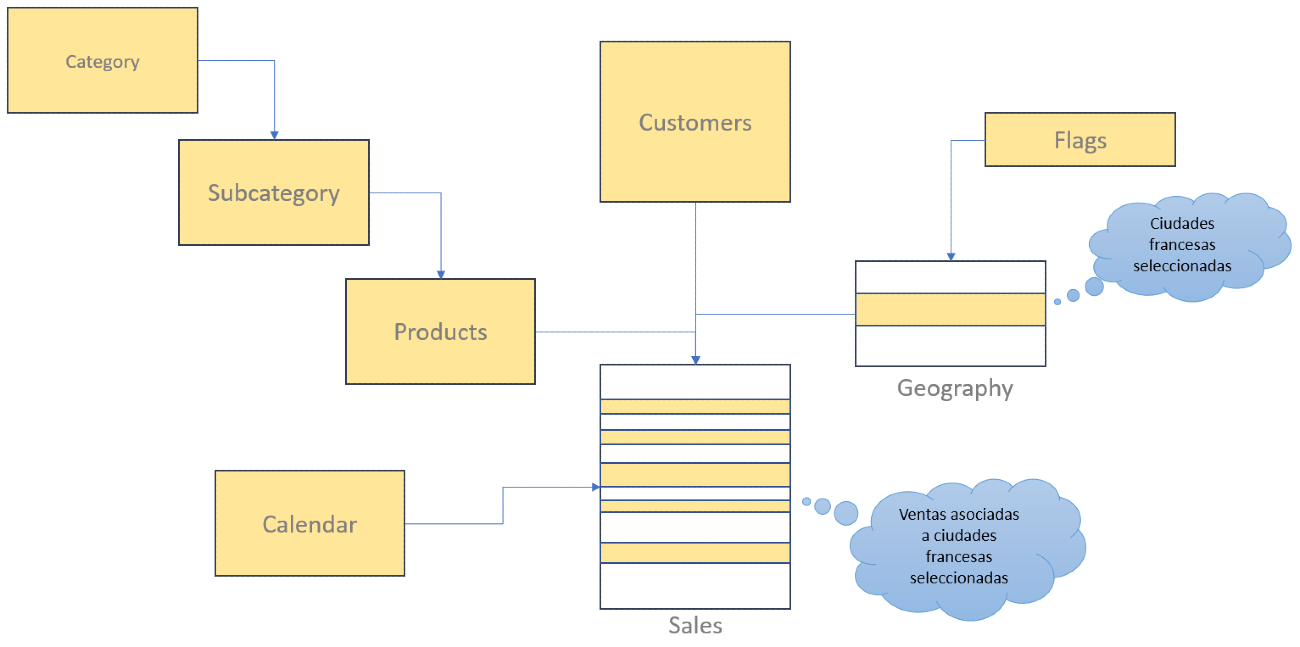
Esto supone que, cuando llegamos a nuestra medida:
AVERAGEX(
Sales,
Sales[Delivery Date] - Sales[Order Date]
)
esa tabla Sales que aparece como primer argumento ya ha sido filtrada, y nuestra función AVERAGEX va a iterar la tabla filtrada, calculando el valor medio de los tiempos de entrega solo para Francia (que es lo que estamos buscando).