Si entrenamos el algoritmo de Regresión Logística sobre estos datos, veremos que el resultado es, en este escenario, mejor que el obtenido con PCA. Dividimos nuestros datos:
X_train, X_test, y_train, y_test = train_test_split(X_lda, y)
Entrenamos el modelo:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
model.fit(X_train, y_train)
Y mostremos las fronteras de decisión:
class_names = ["Clase " + str(n) for n in y.unique()]
show_boundaries(model, X_train, X_test, y_train, y_test, class_names)
show_boundaries(model, X_train, X_test, y_train, y_test, class_names)
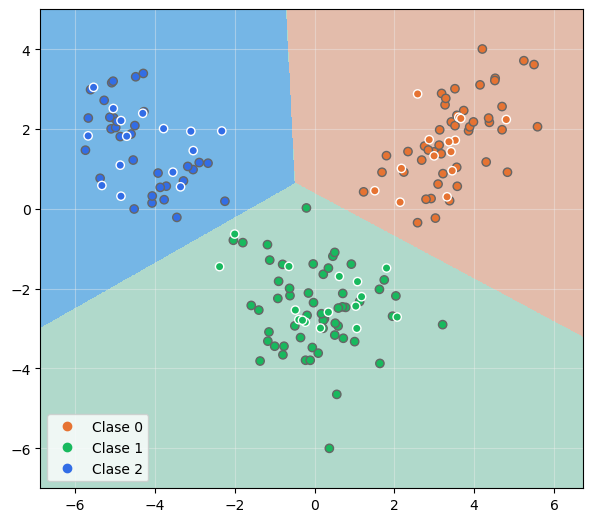
Comprobamos que todas las muestras del conjunto de validación han sido correctamente clasificadas, lo que podríamos comprobar con el método .score() del modelo:
model.score(X_test, y_test)
1.0