Los dataframes tienen un método con el mismo nombre que el método apply de las series, pandas.DataFrame.apply, pero con funcionalidad diferente pues, en el caso de los dataframes, se aplica a lo largo de un eje del dataframe. Esto quiere decir que el argumento de entrada de la función a utilizar no va a ser un simple escalar, sino una serie cuyo índice va a ser el índice de filas del dataframe (si la función se aplica al eje 0) o el índice de columnas del dataframe (si la función se aplica al eje 1). El resultado del método también será una serie que estará formada por los valores calculados.
Por ejemplo, si tenemos el siguiente dataframe con las ventas de los productos A, B, C y D a lo largo de los meses de enero, febrero y marzo:
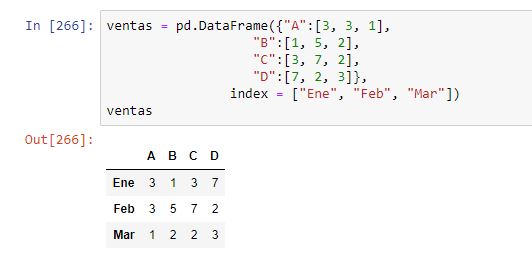
...podríamos estar interesados en calcular el rango en el que se mueven las ventas, es decir, la diferencia entre el mayor y el menor valor de ventas. Para ello, sabiendo que dicho rango se va a aplicar a una fila o a una columna -es decir, a una serie-, definimos la siguiente función:

Esta función acepta un iterable y devuelve la diferencia entre el valor máximo y el mínimo.
Ahora podemos aplicar esta función a nuestro dataframe de ventas. Por defecto se va a aplicar al eje 0 (eje vertical):
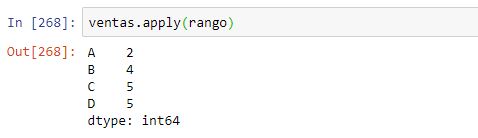
Si nos fijamos en la columna A, el valor máximo es 3 y el mínimo es 1, de forma que su diferencia es 2, tal y como se muestra en el resultado del método apply.
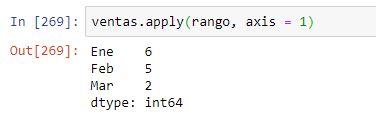
Si aplicamos el método a lo largo del eje 1 (eje horizontal), obtendremos la diferencia entre el mayor y el menor valor de cada fila: