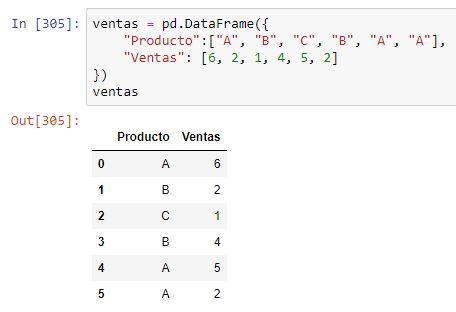
El método pandas.DataFrame.groupby tiene una funcionalidad semejante a la vista para series, con los condicionantes propios de los dataframes: es necesario indicar el eje que contiene el criterio por el que se va a realizar la agrupación. Comencemos con un ejemplo sencillo. Partimos del siguiente dataframe:
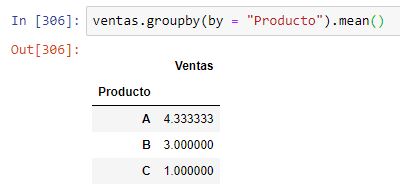
En el caso de los dataframes, el parámetro by puede hacer referencia a una función, a un diccionario, a una etiqueta o a una lista de etiquetas. Si pasamos simplemente la etiqueta "Producto" para indicar que la agrupación se realice según los valores de esta columna, tenemos:
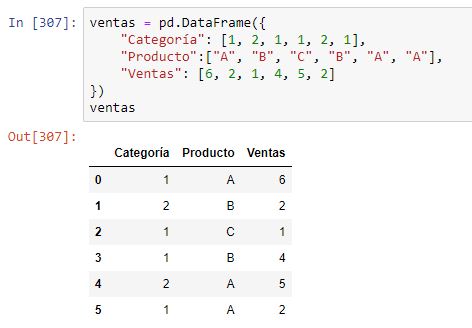
Si quisiéramos realizar la agrupación por más de una columna, bastaría con pasar como argumento una lista con las etiquetas en cuestión. Por ejemplo, consideremos el siguiente caso en el que tenemos las ventas clasificadas por categoría y producto:
Si aplicamos ahora el método groupby con el argumento by = ["Categoría", "Producto"], tenemos:
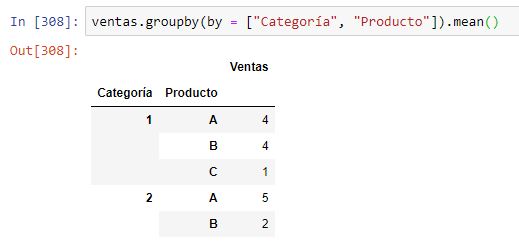
Este ejemplo tiene demasiados pocos datos para ser significativo, pero aun así es posible ver que el método ha agrupado todas las ventas según la combinación de categoría y producto, y se ha calculado el valor medio. Por ejemplo, hay dos ventas de categoría 1 y producto A, de valores 6 y 2. La media, tal y como se muestra en Out[308] es de 4.
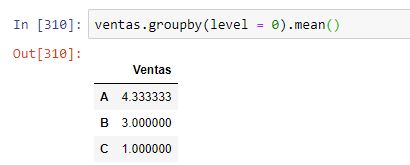
También podríamos usar el parámetro level. En el caso de estar trabajando con dataframes con índices no jerárquicos, basta pasar como valor para este argumento el 0 para que la agrupación se realice según las etiquetas del índice. Por ejemplo, consideremos el siguiente dataframe:
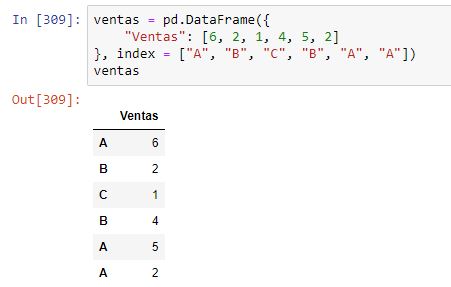
Si ejecutamos el método con el argumento level = 0, obtendríamos el siguiente resultado: