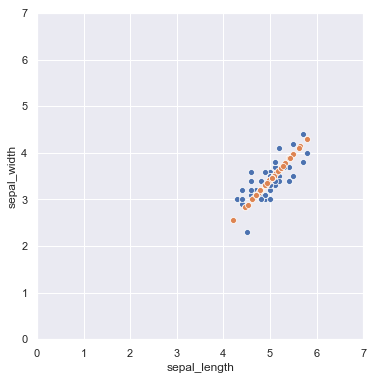
Las imágenes mostradas en la sección anterior se corresponden, de hecho, con datos extraídos del dataset Iris, y más concretamente, con las características "sepal_length" y "sepal_width" de las flores Setosa. Comenzamos, por lo tanto, extrayendo el subconjunto de interés del dataset:
iris = sns.load_dataset("iris")
iris = iris.loc[iris.species == "setosa"][["sepal_length", "sepal_width"]]
iris.head(2)
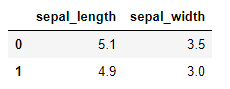
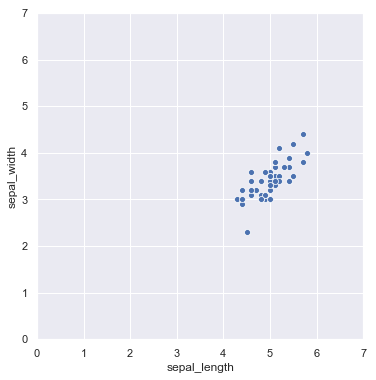
fig = plt.figure(figsize = (6, 6))
ax = plt.axes(aspect = "equal", xlim = (0, 7), ylim = (0, 7))
sns.scatterplot("sepal_length", "sepal_width", data = iris);
Ahora importamos la clase PCA e instanciamos el aprendiz especificando que el número de componentes a extraer es igual a 1:
from sklearn.decomposition import PCA
pca = PCA(n_components = 1, random_state = 0)
Entrenamos y transformamos el dataset:
iris_transformed = pca.fit_transform(iris)
En la variable iris_transformed tenemos los datos transformados que, en este caso, son datos en una estructura de una dimensión:
iris_transformed[:5, :]

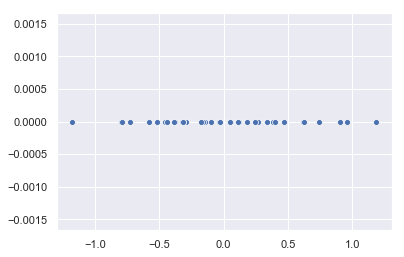
Si quisiéramos, podríamos mostrar estos puntos en el eje x de un espacio bidimensional:
sns.scatterplot(iris_transformed.flatten(), [0] * len(iris_transformed));
Sin embargo, más interesante es mostrarlos directamente sobre la recta del primer componente principal. Para ello podemos usar el método inverse_transform de PCA, que transforma los datos al espacio original:
iris_o_transformed = pca.inverse_transform(iris_transformed)
fig = plt.figure(figsize = (6, 6))
ax = plt.axes(aspect = "equal", xlim = (0, 7), ylim = (0, 7))
sns.scatterplot("sepal_length", "sepal_width", data = iris);
sns.scatterplot(iris_o_transformed[:, 0], iris_o_transformed[:, 1]);