El Pivot Slicer es una (probablemente) potente visualización cuya utilidad queda un tanto limitada por la falta de documentación y por algunas decisiones tomadas en su desarrollo que veremos a continuación. Se muestra a continuación el panel de campos de la visualización:
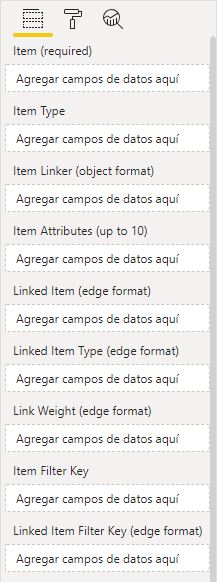
Como puede verse, los campos -aun un tanto desordenados- hacen referencia a dos tipos de objetos: items e items enlazados ("linked items"). El reparto es el siguiente:
Campos relativos a items:
- Item (required)
- Item Type
- Item Attributes (up to 10)
- Item Filter Key
Campos relativos a linked items:
- Item Linker (object format)
- Linked Item (edge format)
- Linked Item Type (edge format)
- Link Weight (edge format)
- Linked Item Filter Key (edge format)
De hecho puede verse que los linked items parecen existir en dos formas: en formato "objeto" y en formato "edge".
Items
Comencemos por lo básico, que es llevar algún campo de nuestro modelo de datos al campo Item (required) de la visualización (campo que, tal y como su nombre indica, es obligatorio). Y solo es posible llevar un único campo. Vamos a llevar uno que contiene el nombre de nuestros clientes, Full Name. Y para ver cómo funciona el slicer, llevamos al informe también una tabla con el listado de clientes, otra con los valores del campo Gender (Female y Male) y una tarjeta de varias filas con varias medidas (ventas totales, unidades vendidas y margen total). De este modo veremos cómo se filtran las tablas al hacer una selección en el slicer:
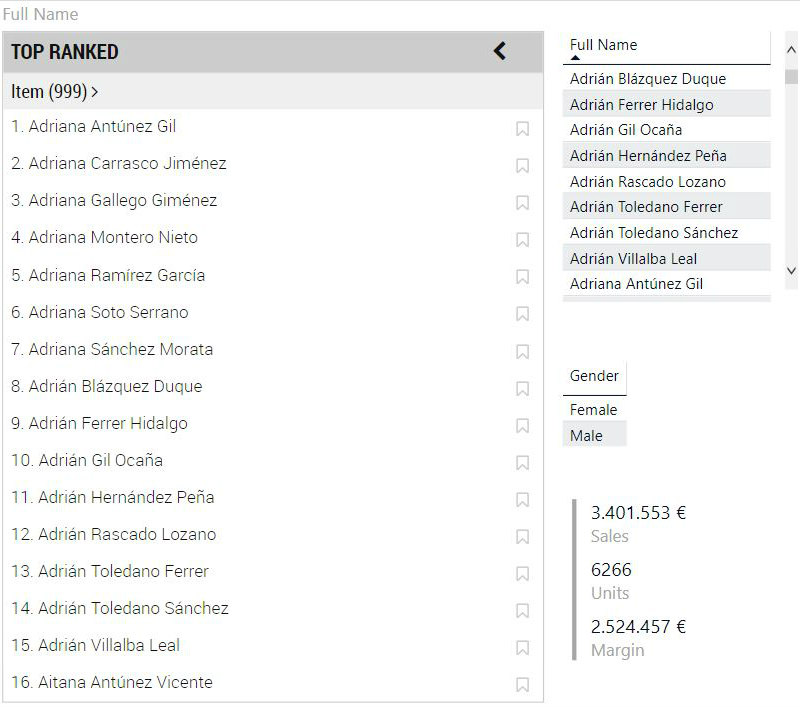
El slicer, en este momento, simplemente muestra los valores del campo que hemos llevado a Item (required): los nombres de los clientes. Se muestra el nombre por defecto que recibe la lista ("Item") y, junto a este nombre, el número de elementos que la componen (999 en nuestro ejemplo).
Si hacemos clic en un nombre de la lista, se selecciona, filtrando también el resto de visualizaciones del informe. En la siguiente imagen se muestra nuestro informe tras haber hecho clic en el nombre de "Adriana Sánchez Morata":
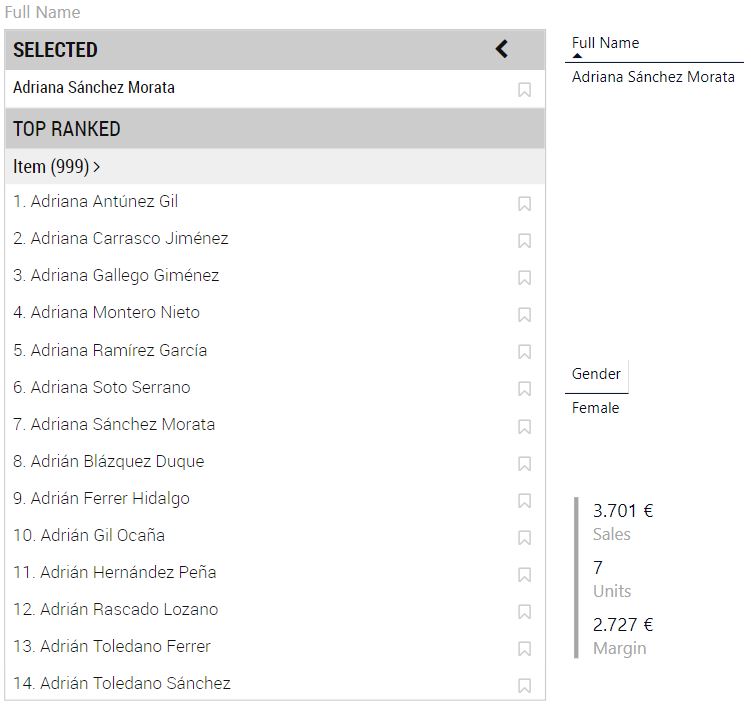
Vemos en la imagen anteior que ha aparecido un bloque ("SELECTED") en la parte superior de la lista con el nombre del elemento seleccionado. Un clic en otro nombre de la lista sustituiría el seleccionado por el nuevo (solo se puede seleccionar uno), y un clic en el nombre incluido en el bloque SELECTED lo deseleccionaría, volviendo al estado inicial.
Item Type
Podemos desagregar nuestros datos utilizando el campo Item Type de la visualización. Por ejemplo, si llevamos el campo Gender que contiene el sexo del cliente a este campo, la visualización muestra el siguiente aspecto:
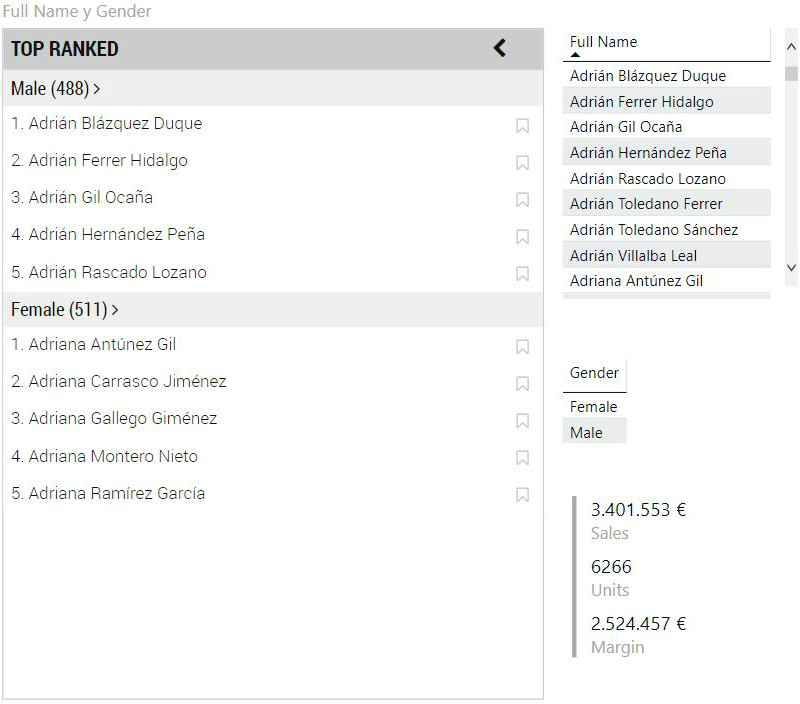
De esta forma puede resultar más sencillo buscar el elemento que queremos seleccionar al tenerlos separados según el criterio escogido. Pero el comportamiento del slicer no ha cambiado: un clic selecciona al elemento, filtrando el resto de visualizaciones, un clic en otro elemento sustituye al que se encuentre en SELECTED por el nuevo, y un clic en el elemento que se encuentre en SELECTED lo deselecciona.
Vemos que en nuestra tabla de clientes hay 488 hombres y 511 mujeres.
Ahora, cuando seleccionamos un elemento se muestra el "tipo" al que pertenece:
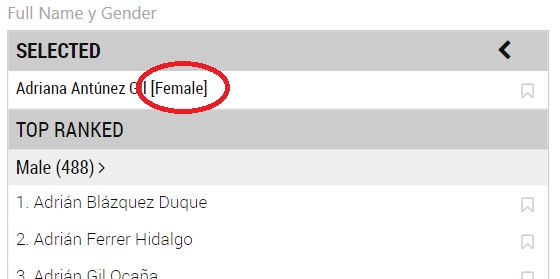
En la esquina superior derecha de la imagen anterior vemos el símbolo "<". Nos sirve para recorrer los estados anteriores por los que hemos pasado. Por ejemplo, seleccionamos a "Adrián Gil Ocaña" y, a continuación, a "Adriana Montero Nieto":
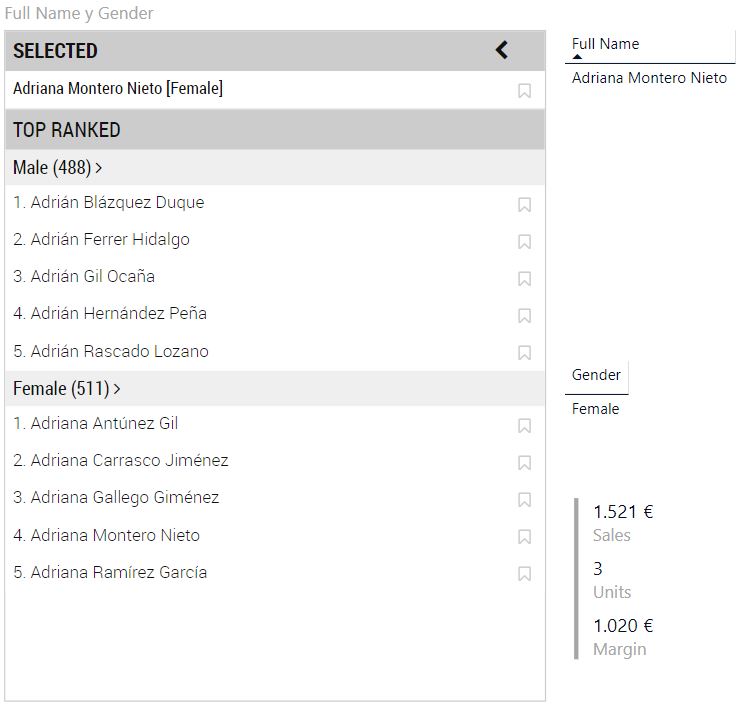
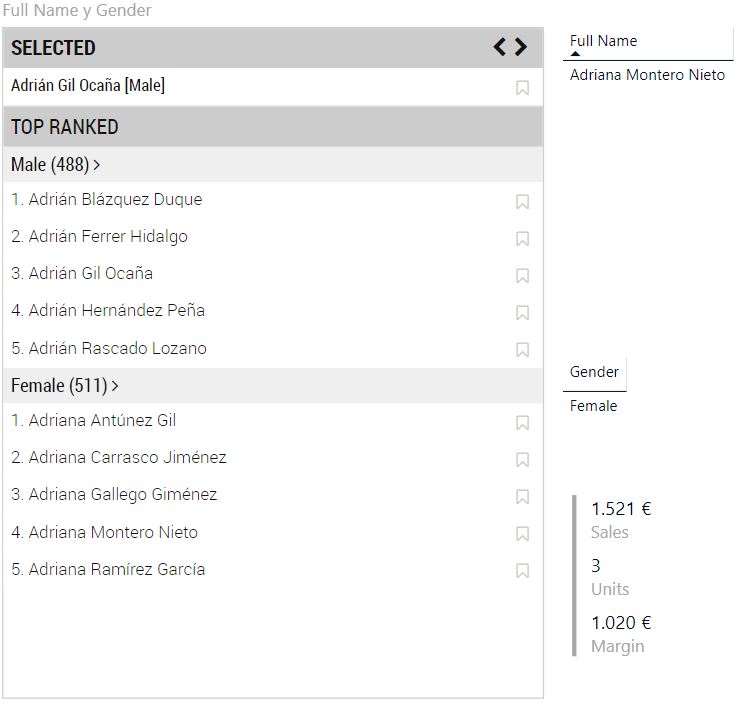
Ahora hacemos clic en el icono mencionado. La visualización mostrará el estado anterior (en el que había seleccionado a "Adrián Gil Ocaña") y el icono cambia para permitirnos seguir retrocediendo o volver al último estado:
Item Attributes
Otro de los campos que se incluyen en la visualización es el de Item Attributes (up to 10). A este campo deberemos arrastrar campos de nuestro modelo de datos (no se permiten medidas) que permitan aplicar un rango a los items (a los clientes en nuestro ejemplo). Por ejemplo, supongamos que el número de unidades adquiridas por cada cliente y el total de ventas (de cada cliente) nos resultan criterios adecuados para la aplicación de estos rangos. Arrastramos entonces tanto el campo Amount (cifra de ventas) como el campo Units al campo mencionado de la visualización (tal y como indica el nombre del campo, el máximo número de campos de nuestro modelo de datos que podemos arrastrar hasta aquí es de 10).
Ahora el icono que nos permitía recorrer el histórico de selecciones se desplaza al centro de la visualización y en su lugar aparece una etiqueta: ITEMS. Un clic en esta etiqueta cambia la visualización para mostrar la pantalla de ATTRIBUTES y nos muestra la siguiente imagen:
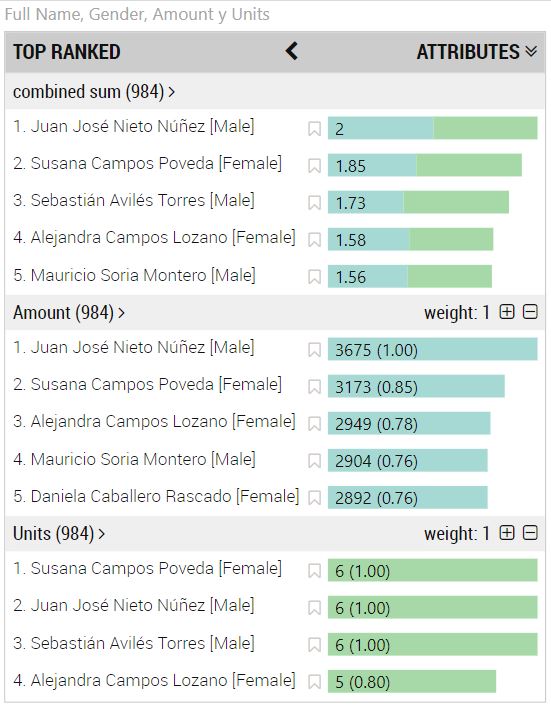
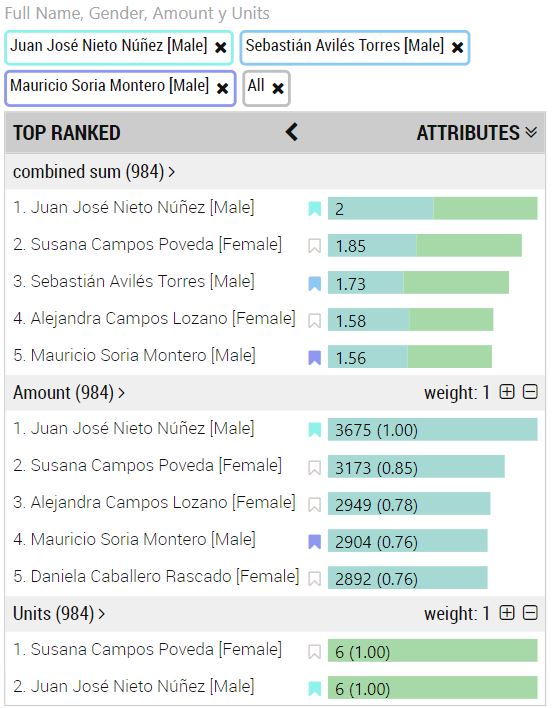
Lo que estamos viendo son tres listados: "combined sum" (en la parte superior), "Amount" (en el centro) y "Units" (en la parte inferior). También vemos que el número de "items" de cada lista es de 984 (señal de que hay otras 15 personas que, a pesar de figurar en la tabla de clientes, no han comprado nunca nada).
La lista inferior, Units, muestra los "items" (clientes) ordenados según cierta cifra (6, 6, 6, 5...) de mayor a menor. Estos números no son el número total de unidades compradas por cada cliente, sino el valor máximo que cada cliente ha adquirido en una única compra. Es decir, si un cliente a realizado 3 compras y el número de unidades ha sido, por ejemplo, 4, 1, y 2, este cliente aparecería en el listado anterior con un 4. Si quisiéramos que la cifra asociada a cada cliente fuese el número total de unidades adquiridas, habría que agregar la información previamente.
La lista central, Amount, hace lo propio, mostrando los clientes ordenados de mayor a menor según otra cifra que, nuevamente, no representa la suma de las ventas realizadas a cada cliente, sino la mayor cifra de las ventas realizadas a cada uno. Otro ejemplo: si un cliente ha realizado tres compras de 3.000, 2.000 y 1.000 euros, en el listado aparecería con 3.000€.
La decisión de mostrar el valor máximo en lugar de la suma o el promedio (y el hecho de no poder cambiarse esta función de agregación) compromete notablemente la utilidad de la visualización. Sería mucho más versátil si pudiésemos escoger la función a aplicar.
En todo caso, lo interesante es lo que tenemos en la lista superior: tal y como se ve en la imagen anterior, las listas inferiores reciben un peso (weight) que, por defecto, toma el valor 1. Además, cada item de las listas recibe un coeficiente relativo al valor máximo de su lista. Por ejemplo, en la imagen anterior vemos que, en la lista de "Amount", el valor máximo es de 3.675, valor que recibe el coeficiente 1.00 (que se muestra a la derecha de dicha cifra). El siguiente valor en la lista es 3.173, que recibe el coeficiente 0.85 (pues esta cifra es aproximadamente el 85% del valor máximo), y así con todos los elementos de la lista. Los elementos de las demás listas (Units solamente en nuestro ejemplo) también reciben un coeficiente semejante que se calculan con respecto al máximo de la lista a la que pertenezca.
Pues bien, la lista superior muestra los clientes según la suma de los coeficientes indicados (para cada cliente) ponderados por los pesos de cada lista. Es decir, nos muestra los "mejores" items según todos nuestros criterios, ponderados según los pesos que hemos dado a cada uno.
Podemos modificar el peso que damos a cada lista haciendo clic en los símbolos + y - que se muestran a la derecha de la etiqueta weight. Por defecto, cada clic añade o resta 0.25, pero podemos modificar este incremento en Formato > Configuration > Attribute Weight Delta.
Las listas pueden tener asignado un peso negativo si es que un valor mayor supone una disminución en el criterio de "calidad" del que estemos hablando. Por ejemplo, si estamos valorando proveedores, el descuento que nos hagan puede ser considerado positivo mientras que el tiempo de entrega (el tiempo que tarden en entregarnos la mercancía) puede ser negativo (un mayor tiempo puede suponer entregar un producto al cliente final más tarde, por ejemplo).
Si hacemos clic en la etiqueta ATTRIBUTES que ahora se muestra en la esquina superior derecha volvemos al listado original (desglosado según el criterio que hayamos llevado a Item Type). Tanto en esta sección de "Items" como en la "Attributes" vemos que a la derecha de los nombres se muestra un icono con aspecto de marcador de libro. Un clic en este icono para un item concreto lo resalta en todas las listas y lo mueve encima de la visualización (sin seleccionarlo). En la siguiente imagen se ha hecho clic en los "marcadores" que acompañan a tres clientes:
La utilidad de esta herramienta puede ser la de ver en qué posiciones queda en las diferentes listas un elemento concreto, por ejemplo.
Podemos eliminar uno de estos items de dicha zona haciendo clic en el aspa que lo acompaña, o podemos seleccionarlo haciendo clic en el nombre (en cuyo caso pasaría a la zona de SELECTED y filtraría el resto de visualizaciones). Un clic en el aspa que acompaña a la etiqueta All eliminaría todos los nombres situados en la zona superior de la visualización.
Linked Items
Y comentamos al comienzo que la visualización hace referencia a "items" (ya vistos) y a "linked items" (elementos enlazados). Veamos cuál es la idea que hay detrás de esto: si los items son, por ejemplo, clientes, los elementos enlazados pueden ser los productos que adquieren, o las categorías de éstos, o los países en los que se realizan las compras, por poner algunos ejemplos. Y una vez establecidos ambos elementos, items y linked items, podemos estar interesados en ordenar unos en función de los otros: Suponiendo que los items sean clientes y los linked items sean productos ¿cuáles son los clientes que más productos adquieren? o ¿qué productos son los más adquiridos? o ¿qué productos son los más adquiridos si damos a cada uno un peso equivalente a su precio? Este es el tipo de información a la que vamos a poder acceder.
Ya hemos visto que los elementos enlazados parecen encontrarse en dos formas: formato de "objeto" (campo Item Linker (object format)) y formato de "edge" (todos los demás campos que hacen referencia a elementos enlazados). Y digo que "parecen encontrarse" porque todo apunta a que tenemos que escoger entre un formato u otro, ya que si hacemos uso de campos de los dos tipos, la visualización deja de ofrecer información sobre elementos enlazados.
Así que comencemos por lo que parece ser la opción más simple, el formato de objeto.
Item Linker (object format)
Al campo de la visualización Item Linker (object format) podemos llevar un campo que provoca que se muestren otras dos secciones en la visualización (accesible haciendo clics en la etiqueta superior derecha de la misma), de nombre LINKS y JOINT LINKS respectivamente, ambas con contenidos aparentemente idénticos que muestran el recuento de los elementos del campo que hemos llevado que estén asociados a cada item. Por ejemplo, si llevamos el campo Product Name de nuestra tabla de productos y nos movemos a la nueva sección LINKS (haciendo clic en la ya mencionada etiqueta de la esquina superior derecha) la visualización muestra lo siguiente:
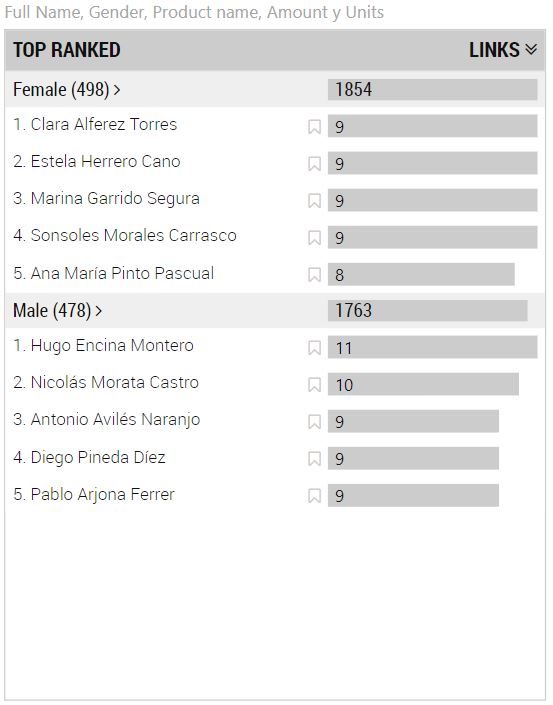
Lo que estamos viendo es el número de productos adquiridos por cada cliente (número de productos, no número de unidades: si un cliente ha realizado una compra de 3 unidades del producto A y 5 del producto B, aparecería con un 2 -dos productos adquiridos-).
Linked Item (edge format)
Otro campo de la visualización, Linked Item (edge format) aparentemente tiene el mismo comportamiento que éste último mencionado salvo que hagamos uso del resto de campos de la visualización que se refieren a este tipo de elementos enlazados. Si hacemos uso de este campo llevando el campo de Product Name (para lo cual deberemos eliminar el posible campo que haya en Item Linker (object format)), la etiqueta que se muestra en la esquina superior derecha de la visualización es "OUT LINKS".
También se crea en este caso otra sección de nombre "JOINT OUT LINKS" (con los mismos contenidos que OUT LINKS) y una tercera de nombre "IN LINKS" que muestra los elementos del nuevo campo según el número de veces que aparecen relacionados con nuestros items originales (es decir, el número de clientes que los han adquirido):
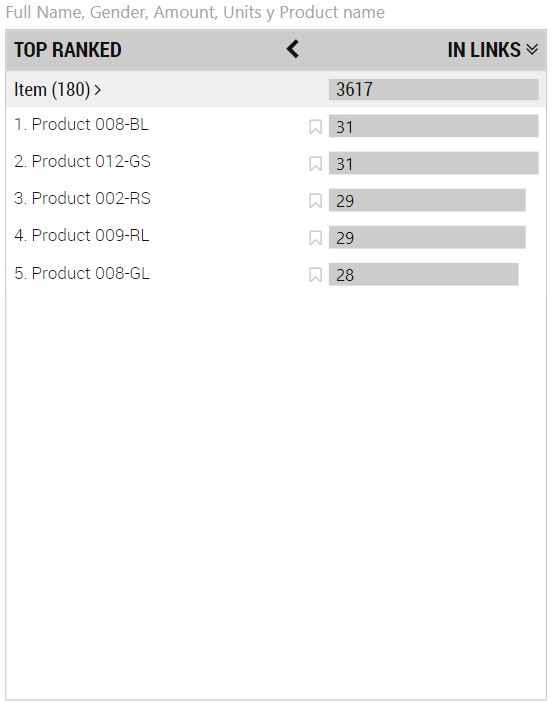
En la imagen anterior vemos que los productos que más clientes han adquirido son el "Product 008-BL" y el "Product 012-GS", adquiridos por 31 clientes. Nuevamente, no estamos hablando de los productos más veces vendidos, ni con más unidades vendidas, sino de los productos que más clientes han comprado. Por ejemplo, si el producto A ha sido adquirido por un único cliente en una compra que involucra 1.000 unidades, y el producto B ha sido adquirido por dos clientes involucrando una única unidad en cada una de las compras, en la lista mostrada en la imagen aparecerían con los valores 2 y 1 respectivamente.
Linked Item Type (edge format)
Podemos desagregar estos elementos enlazados si arrastramos una dimensión de dichos elementos al campo de la visualización Linked Item Type (edge format). Por ejemplo, si arrastramos el campo Category (categoría de cada producto) a este campo, la visualización muestra, en la sección IN LINKS, lo siguiente:
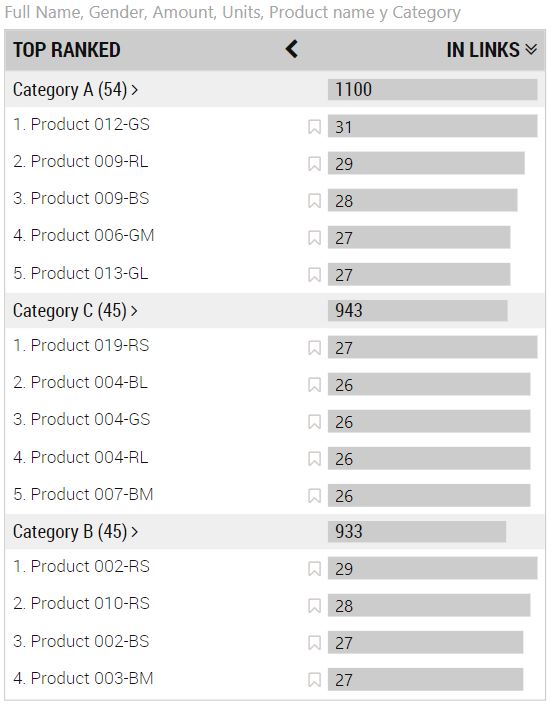
Es decir, vemos los productos vendidos a mayor número de clientes clasificados por categoría.
Pero podemos estar interesados no en saber qué productos fueron los vendidos a mayor número de clientes, sino de acuerdo al precio de cada producto, por ejemplo. Veamos qué obtenemos si hacemos uso del campo Link Weight (edge format) arrastrando el campo Price (precio de cada producto) al campo en cuestión:
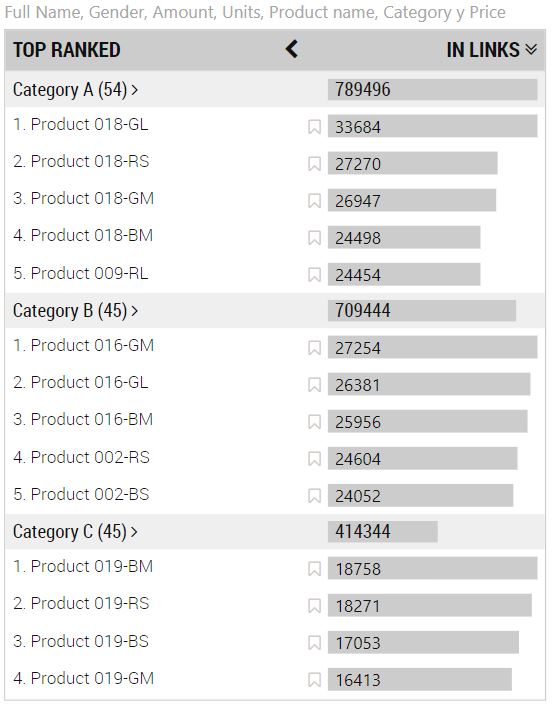
Ahora, el criterio de clasificación es el precio de cada producto multiplicado por el número de clientes que lo han adquirido.
Filters
Hay todavía dos campos que no hemos mencionado: Item Filter Key y Linked Item Filter Key (edge format), pero su utilidad es todo un misterio, pues no parecen influir en la visualización (al menos yo no he averiguado).
Resumen
En resumen, buena y original idea, compleja implementación, nula documentación y algunas decisiones mejorables hacen de esta visualización algo de lo que resulta muy difícil sacar provecho. Más parece un producto en fase alfa (en fase de desarrollo) que un desarrollo terminado. Dudo que lo vaya a utilizar mientras no mejore su usabilidad.