DataFrame.rank(
axis=0,
method='average',
numeric_only=None,
na_option='keep',
ascending=True,
pct=False
)
El método rank de un DataFrame pandas devuelve otro DataFrame pandas en el que los valores son el resultado de asignar rangos (desde 1 hasta n) a los valores del DataFrame original considerándolos ordenados, por defecto, de menor a mayor a lo largo del eje 0. Es decir, el menor valor de una columna recibe el rango 1, el siguiente el 2, etc. El parámetro method controla el método de asignación de rangos a valores coincidentes.
El índice del DataFrame original se mantiene. Los rangos asignados son números reales.
- axis: (0 o "index" -valor por defecto-, 1 o "columns" ) Eje a lo largo del cual se calculan los rangos.
- method: ("average" -valor por defecto-, "min", "max", "first", "dense") Criterio para asignar rangos a valores coincidentes. Estos criterios parten de los rangos que se asignarían al grupo de valores si cada valor recibiese un rango distinto (véanse ejemplos más adelante).
- "average": (Valor por defecto) devuelve el valor medio de los rangos que se asignarían al grupo.
- "min": Valor mínimo del grupo. El siguiente valor (fuera del grupo) recibe como rango el asignado al grupo + n, siendo n el número de elementos del grupo.
- "max": Valor máximo del grupo.
- "first": Rangos asignados según el orden en el que los valores aparecen en la serie.
- "dense": semejante a "min" pero el siguiente valor (fuera del grupo) recibe como rango el asignado al grupo + 1.
- na_option: ("keep" -valor por defecto-, "top", "bottom"). Controla la gestión de los valores nulos:
- "keep": Asigna el rango NaN a los valores NaN.
- "top": Asigna el menor rango a los valores NaN.
- "bottom": Asigna el mayor rango a los valores NaN.
- ascending: (Booleano, True por defecto). Si toma el valor True los rangos se asignarán de menor a mayor valor (el menor valor recibirá el rango 1.0).
- pct: (Booleano, False por defecto). Controla si los rangos se mostrarán con formato de fracción.
El método pandas.DataFrame.rank devuelve un DataFrame pandas.
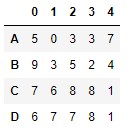
Para probar este método, generemos un DataFrame formado por valores numéricos aleatorios:
import numpy as np
import pandas as pd
np.random.seed(0)
df = pd.DataFrame(np.random.randint(0, 10, size = (4, 5)), index = list("ABCD"))
df
Ahora ejecutamos el método con sus parámetros por defecto:
df.rank()
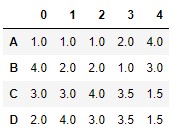
Observamos que, por defecto, los rangos se han asignado a lo largo del eje 0 (eje vertical). La columna 1 estaba formada por valores crecientes (0, 3, 6 y 7), por lo que los rangos asignados son 1.0, 2.0, 3.0 y 4.0, respectivamente.
En la columna 0 el menor valor es el 5 (índice "A"), que recibe el rango 1.0. El siguiente valor -considerándolos de menor a mayor- es el número 6 (índice "D") que recibe el rango 2.0.
En la columna 4 hay dos valores 1. Si recibiesen rangos diferentes, al tratarse de los valores más bajos, recibirían los rangos 1.0 y 2.0 (o viceversa, es indiferente), por lo que se muestran en el resultado con el valor medio de dichos rangos (1.5).
Algo semejante observamos en la columna 3, en la que hay dos valores 8 (los más elevados) que recibirían los rangos 3 y 4 (si los rangos asignados fuesen diferentes), motivo por el que reciben el rango 3.5.
Si, en el ejemplo anterior, quisiéramos modificar el comportamiento para los valores repetidos, podríamos hacerlo añadiendo el parámetro method. Por ejemplo, podríamos asignar el menor rango (de los que se asignarían si los rangos fuesen diferentes) con el siguiente código:
df.rank(method = "min")
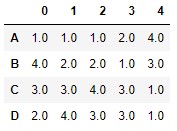
En este caso, los dos valores 1 presentes en la columna 4 han recibido un rango de 1.0 (que es el menor de los rangos 1.0 y 2.0 que se asignarían si los rangos fuesen distintos). Vemos, sin embargo, que ningún número ha recibido el rango 2.0.
Si deseásemos que la asignación de rangos a valores iguales fuese la determinada por el parámetro "min" visto pero se realizase sin dejar huecos, podríamos conseguirlo asignando el valor "dense" al parámetro method:
df.rank(method = "dense")
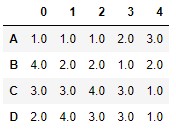
Vemos que los dos valores 1 de la columna 4 siguen recibiendo el rango 1.0, pero el siguiente rango asignado es ahora 2.0.
El parámetro ascending controla la forma de asignar rangos: suponiendo los valores ordenados de menor a mayor (valor por defecto) u ordenados de mayor a menor, lo que podemos controlar de la siguiente forma:
df.rank(ascending = False)
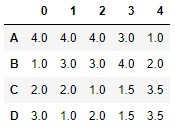
Ahora los rangos 1.0 se asignan a los mayores valores de cada columna.
Si quisiéramos que los rangos se asignasen a lo largo del eje horizontal, bastaría con especificar el eje 1 (o "index") en el parámetro axes:
df
df.rank(axis = 1)
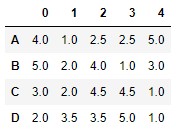
Ahora, la fila "A" que estaba compuesta por los valores 5, 0, 3, 3, 7 recibe los rangos 4.0, 1.0, 2.5, 2.5 y 5.0. El número 0 -el menor de todos- es el que ha recibido el rango 1.0. Los valores 3 que aparecen dos veces reciben el rango 2.5 (media de 2.0 y 3.0).
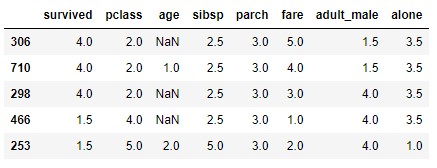
Este método no solo se aplica a valores numéricos. Carguemos en la variable df 5 registros aleatorios extraídos del dataset titanic que podemos descargar de la librería seaborn:
import seaborn as sns
titanic = sns.load_dataset("titanic").sample(5)
titanic

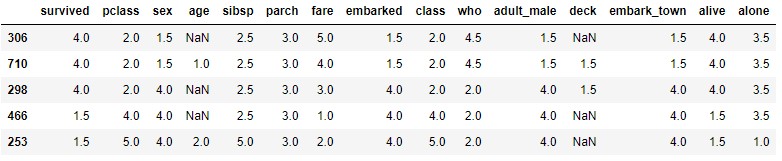
Si ahora aplicamos el método rank vemos que todas las columnas reciben rangos:
titanic.rank()
Podemos seleccionar solo las columnas numéricas con el parámetro numeric_only:
titanic.rank(numeric_only = True)