sklearn.model_selection.train_test_split(*arrays, **options)
La función sklearn.model_selection.train_test_split nos permite dividir un dataset en dos bloques, típicamente bloques destinados al entrenamiento y validación del modelo (llamemos a estos bloques "bloque de entrenamiento " y "bloque de pruebas" para mantener la coherencia con el nombre de la función).
Para probarlo comencemos cargando un dataset:
titanic = sns.load_dataset("titanic")
titanic.head(1)

Veamos el tamaño de este dataset:
891 filas y 15 características (de las que una de ellas es la variable objetivo).
Si pasamos como argumento a train_test_split el dataset completo, nos devolverá dos subconjuntos del mismo, escogiendo un cierto número de filas para el subconjunto de entrenamiento y el resto para el subconjunto de pruebas:
from sklearn.model_selection import train_test_split
train, test = train_test_split(titanic, random_state = 0)
print(train.shape)
print(test.shape)
Salvo que se le indique otra cosa, la función train_test_split añade al bloque de entrenamiento el 75% de los registros, y al bloque de pruebas el 25% restante. Podemos controlar estas cifras con los parámetros train_size y test_size. Estos parámetros pueden ser números enteros, indicando exactamente el número de registros a incluir, o un número real, en cuyo caso indican el porcentaje del total de registros a incluir.
Una vez generados los bloques de entrenamiento y pruebas, podemos extraer la variable objetivo para crear, de esta forma, las estructuras que típicamente exigen los algoritmos para su entrenamiento.
El parámetro random_state simplemente fija una semilla para el generador de números aleatorios, lo que permite reproducir la función.
El parámetro shuffle (que toma el valor True por defecto) especifica si los registros deberán ser desordenados previamente o no.
Si pasamos a la función, no un dataset, sino dos estructuras de la misma longitud (típicamente el bloque de características y la variable objetivo), train_test_split va a generar bloques de entrenamiento y pruebas para ambas estructuras, haciendo innecesaria la división posterior entre bloque de características y variable objetivo:
y = titanic.pop("survived")
X = titanic
X_train, y_train, X_test, y_test = train_test_split(X, y)
X_train.shape
X_train.head(2)

La función train_test_split divide el dataset de forma aleatoria, lo que puede provocar que la distribución de alguna característica no sea la esperada. Veamos un ejemplo con el mismo dataset:
titanic = sns.load_dataset("titanic")
train, test = train_test_split(titanic)
La característica "who" del dataset Titanic indica si el pasajero en cuestión era un hombre adulto, una mujer adulta o un niño. Comencemos viendo cuál es el porcentaje de estos valores en el dataset original:
titanic.groupby("who")["survived"].count()/len(titanic)
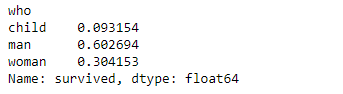
Y veamos ahora cuál es el porcentaje de estos registros en los bloques train y test generados:
train.groupby("who")["survived"].count()/len(train)
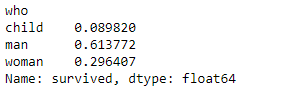
test.groupby("who")["survived"].count()/len(test)
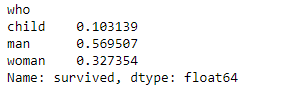
Aun cuando esta característica está razonablemente bien distribuida, vemos que hay diferencias con respecto a la distribución original en el dataset de hasta un 3% (por ejemplo en el porcentaje de hombres adultos del bloque de pruebas).
Pues bien, el parámetro stratify nos permite generar los bloques de entrenamiento y pruebas preservando en ambos el porcentaje de las muestras del dataset original. Para ello hay que indicar en este parámetro cuál es el array de valores -que se asociarán a los datos- que determinan las etiquetas cuyas distribuciones se desea preservar. El ejemplo más sencillo es cuando pasamos a este parámetro una característica del dataset:
train, test = train_test_split(titanic, stratify = titanic["who"])
Si ahora volvemos a analizar el porcentaje de muestras con los valores que toma esta característica en los bloques de datos generados:
train.groupby("who")["survived"].count()/len(train)
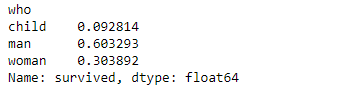
test.groupby("who")["survived"].count()/len(test)
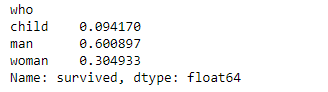
...comprobamos que son cifras muy próximas a las originales, tal y como queríamos.
Esta opción está especialmente indicada en datasets muy desequilibrados, en los que una división del mismo puede incluso dejar todos los registros con cierto valor en una característica en un único bloque.