En este escenario partimos de un DataFrame conteniendo valores nulos en alguna de sus características, por ejemplo, el dataset del Titanic proveído por seaborn:
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset("titanic")
titanic.head()
Podemos comprobar el tamaño del dataset y el número de nulos en la columna "age", por ejemplo:
titanic.shape
titanic.age.isnull().sum()
El objetivo es eliminar del DataFrame titanic las filas que cumplan una cierta condición, por ejemplo, que tomen un valor nulo en el campo "age".
La función drop de pandas elimina filas de un DataFrame, pero exige pasar como argumento las etiquetas del índice que corresponda (del índice de filas si queremos eliminar filas, o del índice de columnas si queremos eliminar columnas), de forma que la pregunta es: ¿Cómo conseguimos los índices de las filas que cumplen una cierta condición? Y la respuesta es: filtrando el DataFrame y utilizando el atributo index. Hagámoslo por partes. En primer lugar extraigamos las filas que cumplen la condición deseada:
df = titanic[titanic.age.isnull()]
df.shape
Comprobamos que, efectivamente, hemos extraído el número correcto de filas. Ahora, con el atributo index podemos extraer los índices de filas de dicho subconjunto del DataFrame inicial:
df.index
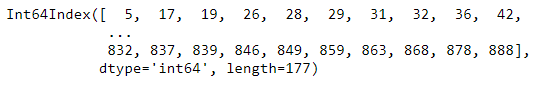
Ahora ya podemos aplicar la función drop a nuestro DataFrame inicial:
titanic.drop(titanic[titanic.age.isnull()].index, inplace = True)
titanic.shape
Comprobamos que han quedado los 714 (= 891 - 177) registros esperados. Si quisiéramos confirmar el número de nulos en la columna "age":
titanic.age.isnull().sum()
0