Supongamos que estamos trabajando con un dataframe como el del Titanic que podemos descargar de seaborn:
import numpy as np
import seaborn as sns
titanic = sns.load_dataset("titanic")
titanic.head()

...y queremos seleccionar las características numéricas. Tenemos varias opciones:
A mano
Obviamente podemos seleccionar éstas manualmente:
seleccion = titanic[["survived", "pclass", "age", "sibsp", "parch", "fare"]]
seleccion.head()
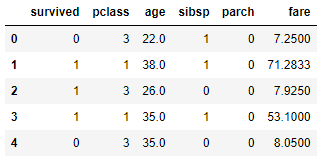
...pero, por supuesto, ésta es la última opción a considerar, pues deseamos llegar a un método "automátivo" que sirva para dataframes de cualquier tamaño.
Con un bucle for
La segunda opción es revisar los tipos de las columnas e ir extrayendo aquellos que nos interesan, que son los que contienen los textos "int" o "float":
features = []
for c in titanic.columns:
t = str(titanic[c].dtype)
if "int" in t or "float" in t:
features.append(c)
features
Con el método _get_numeric_data
Otro método es utilizar el método _get_numeric_data:
titanic._get_numeric_data().head()
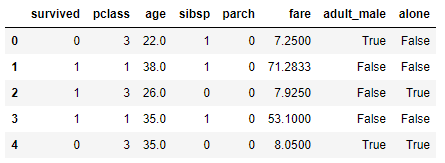
El problema de este método es que considera las características booleanas como numéricas también.
Con el método select_dtypes
El método select_dtypes asociado a un dataframe permite extraer (o excluir) las características con cierto tipo. El inconveniente es que resulta necesario incluir todos los posibles tipos en los que estamos interesados:
seleccion = titanic.select_dtypes(include = ["int16", "int32", "int64", "float16", "float32", "float64"])
seleccion.head()
Con el método select_dtypes y "number"
Podemos simplificar el método anterior incluyendo como listado de tipos a incluir la función numpy.number (función que no aparece en la documentación de NumPy) o, simplemente, "number":
seleccion = titanic.select_dtypes(include = ["number"])
seleccion.head()