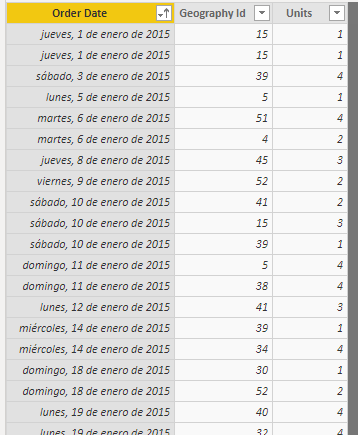
En este escenario queremos ordenar un conjunto de localizaciones (es decir, queremos asignarles un rango) según el número de unidades vendidas en cada una de ellas. Partimos de un listado ("Movements") de ventas en el que se incluye información sobre la fecha de la venta, la zona geográfica en la que se produjo y el número de unidades vendidas:
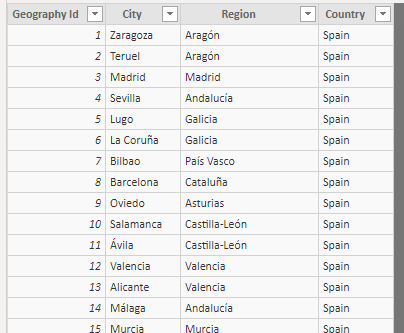
Una segunda tabla ("Geography") incluye información sobre las zonas geográficas en cuestión:
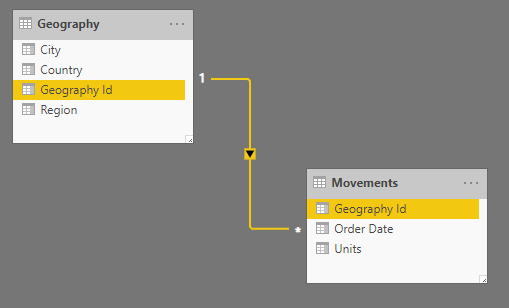
Estas tablas están relacionadas a través del campo Geography Id:
Como sabemos, la función RANKX permite asignar rangos a las filas de una tabla según los resultados que se obtengan al evaluar una expresión. El problema surge precisamente en la evaluación de esta expresión. Veamos por qué: Comencemos añadiendo una nueva columna a la tabla de Geography con el siguiente código que supuestamente asigna rangos a cada fila de la tabla según el número total de unidades vendidas:
Rank = RANKX(
Geography;
SUM(Movements[Units])
)
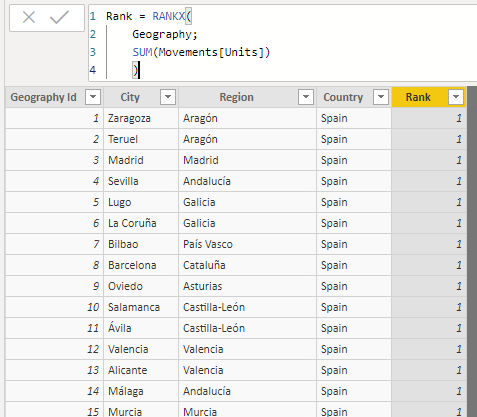
El resultado es de 1 para todas las filas -lo que, obviamente, no es lo que esperábamos-. El problema surge del hecho de que la función SUM utilizada no es capaz de adaptarse al contexto de fila, y, en cada una de las ejecuciones (una por fila)- devuelve la suma de toda la columna Movements[Units]. Para permitir la transición entre ambos tipos de contexto deberemos utilizar la función CALCULATE:
Rank = RANKX(
Geography;
CALCULATE(SUM(Movements[Units]))
)
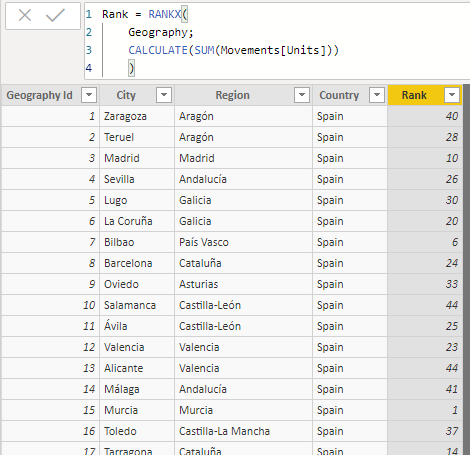
Para confirmar que el resultado es el correcto, definamos una medida que sume el número de unidades vendidas:
Sum of Units = SUM(Movements[Units])
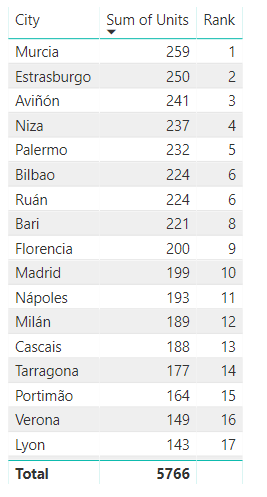
...y llevemos la lista de ciudades, la medida creada y el rango asignado a una visualización tipo tabla, ordenándola de mayor a menor según el valor de la medida: