En su forma más básica, esta función -semejante a la anterior- va a recibir como primeros argumentos las columnas en torno a cuyos valores queremos realizar la agregación y, a continuación, parejas de nombre de columna / expresión DAX. Esta función fue creada después de SUMMARIZE y se considera más eficiente.
Repitamos el ejemplo anterior, agrupando por país las ventas realizadas. Su código sería el siguiente:
SUMMARIZECOLUMNS(
Geography[Country],
"Sales", [Sales]
)
El primer argumento es la columna Geography[Country] según cuyos valores queremos realizar la agregación y, a continuación, el nombre de la columna a crear (“Sales”) y la expresión que va a definir el contenido de la columna (en este caso la medida [Sales]). También en este caso la evaluación de las expresiones se va a realizar en contexto de filtro, por lo que la expresión DAX anterior también habría podido ser la siguiente:
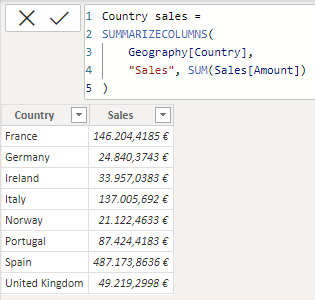
SUMMARIZECOLUMNS(
Geography[Country],
"Sales", SUM(Sales[Amount])
)
La tabla resultante en ambos casos es la misma:
Por supuesto, también aquí podríamos haber añadido más de una columna de agregación, y más de una columna calculada:
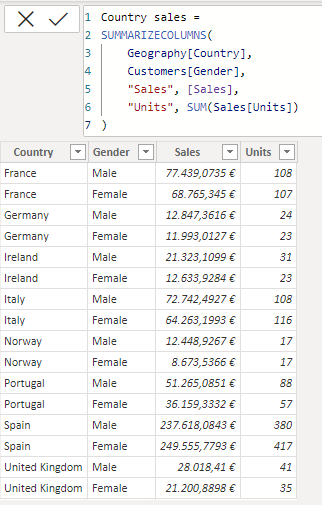
SUMMARIZECOLUMNS(
Geography[Country],
Customers[Gender],
"Sales", [Sales],
"Units", SUM(Sales[Units])
)
Obsérvese que, en este caso, estamos agregando las métricas involucradas (suma del campo Sales[Amount] y suma del campo Sales[Units]) según campos que se encuentran en diferentes tablas (el campo Country en Geography y el campo Gender en Customers). La máquina DAX va a cruzar todos los valores de ambas columnas y, para cada pareja, va a calcular las métricas en el contexto de filtro resultante. Así, por ejemplo, para la combinación de “France” y “Male”, las dos tablas van a filtrarse según dichos criterios, lo que provocará que la tabla Sales también se filtre para dejar visibles solo las ventas realizadas a hombres en Francia: