Una alternativa a esta tabla que contiene toda la información es llevar la información repetida a tablas independientes en la que dicha información solo aparezca una vez. Por ejemplo:
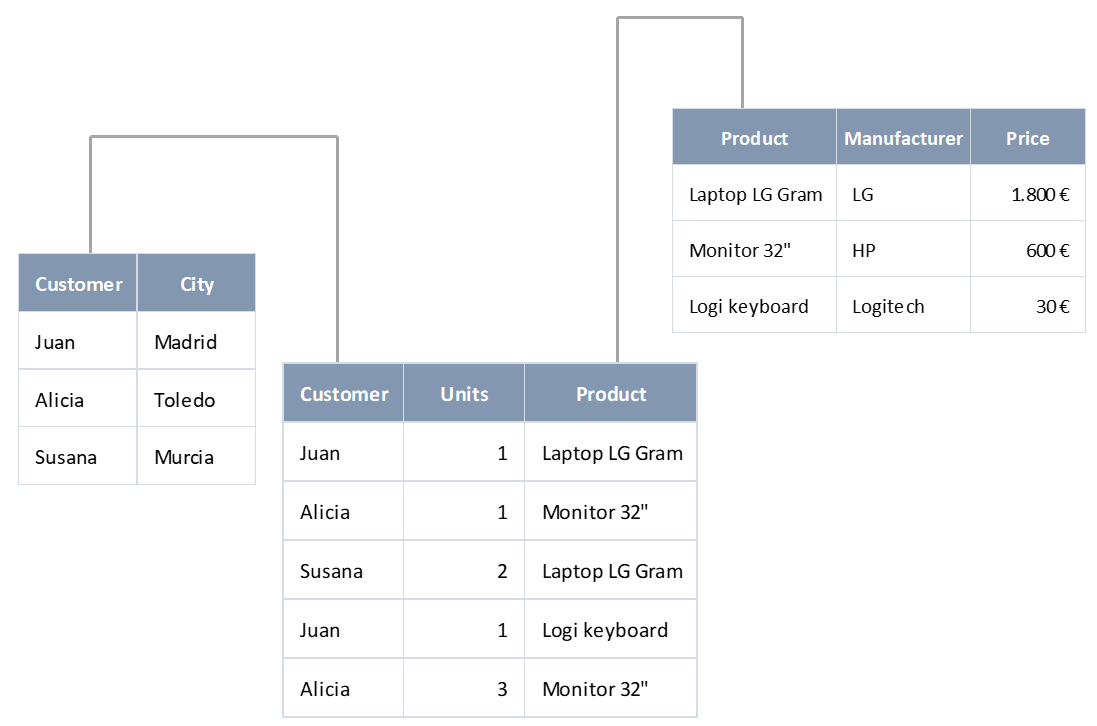
Vemos que, junto a nuestra tabla original de ventas (que se muestra en el centro), tenemos una tabla de clientes (a la izquierda) en la que aparece cada cliente una única vez junto a la ciudad en la que vive. Y tenemos también una tabla de productos (a la derecha) en la que aparecen los nombres de los productos una única vez junto con el fabricante y el precio de venta.
Ahora, si estamos visualizando la tabla de ventas y queremos saber dónde vive el cliente de nuestra primera venta (Juan), no tendríamos más que ir a la tabla de clientes, buscar la fila que contiene la información de Juan y extraer el valor del campo “City”. O si quisiéramos saber cuál fue el precio de venta de dicha transacción, no tendríamos más que ir a la tabla de productos, buscar el producto “Laptop LG gram” y extraer el contenido de la columna “Price”. Una ventaja de este enfoque es que ahorramos espacio en memoria y en disco al evitar tener información duplicada. La desventaja es que ahora tenemos que consultar otras tablas para obtener cierta información, y esta consulta exige un tipo de operación denominada “combinación” (“join” en la literatura en inglés) que resulta un tanto costosa en términos de procesador y memoria (memoria que, en todo caso, se libera una vez se completa el join).
Ahora bien, una vez que hemos separado nuestra tabla original en tres, tenemos que relacionarlas entre sí de forma que, a partir de un registro (fila) de una tabla, podamos acceder al registro o registros correspondientes en otra. Estas relaciones son las que, en la imagen anterior, están representadas por líneas uniendo las tablas entre sí.