Para ver este algoritmo en funcionamiento partamos de los mismos datos que hemos visto en la sección anterior que, por cierto, son el largo y ancho de los sépalos del dataset Iris:
iris = sns.load_dataset("iris")
sns.scatterplot("sepal_length", "sepal_width", data = iris, hue = "species");
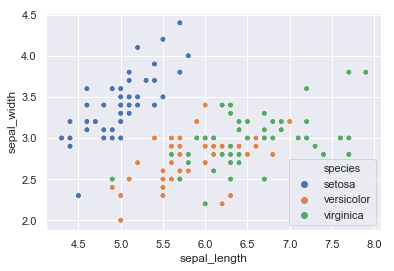
En la imagen anterior los puntos se muestran coloreados según la especie a la que pertenece cada muestra, pero para probar este algoritmo de clustering lo que queremos que vea no es esto, sino los puntos sin clasificar:
sns.scatterplot("sepal_length", "sepal_width", data = iris);
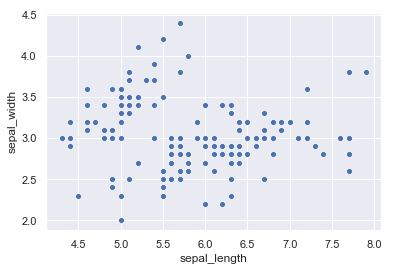
Importamos e instanciamos entonces el algoritmo especificando que se deben crear 3 clusters (suponemos que sabemos este dato):
from sklearn.cluster import KMeans
model = KMeans(n_clusters = 3, random_state = 0)
A continuación lo entrenamos (solo con las dos características con las que estamos trabajando):
model.fit(iris[["sepal_length", "sepal_width"]])

Ahora vamos a realizar la predicción sobre los mismos datos, que vamos a asignar a una nueva columna ("cluster") en el dataframe iris:
iris["cluster"] = model.predict(iris[["sepal_length", "sepal_width"]])
Veamos una muestra del dataframe iris en este momento:
iris.sample(5, random_state = 0)
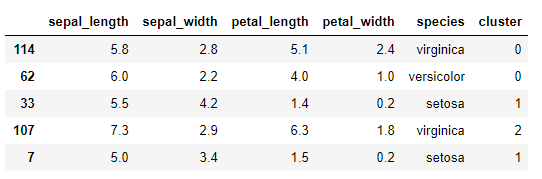
Vemos la nueva columna que, para la métrica usada por el k-Means, guarda un notable parecido con la información contenida en la característica "species", al menos para los 5 registros mostrados. De hecho, si mostramos en una gráfica la distribución original y los puntos indicando el cluster al que han sido asignados:
fig, ax = plt.subplots(2, 1, figsize = (6, 8))
sns.scatterplot("sepal_length", "sepal_width", data = iris, hue = "species", ax = ax[0]);
sns.scatterplot("sepal_length", "sepal_width", data = iris, hue = "cluster",
palette = "gist_stern", ax = ax[1]);
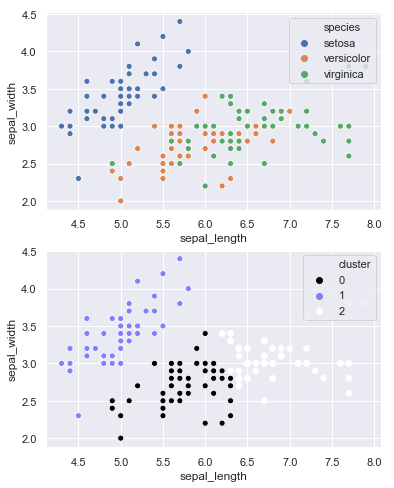
...comprobamos que los clusters resultantes separan razonablemente bien las flores según su especie.
El método score del modelo generado nos devuelve una medida del grado de homogeneidad de los clusters generados:
model.score(iris[["sepal_length", "sepal_width"]])
Mostremos la matriz de confusión resultante. Como la característica "species" contiene textos ("virginica", "setosa" o "versicolor") y la característica "cluster" contiene números (0, 1 o 2), necesitamos convertir una en el equivalente de la otra. Convirtamos los textos en números, por ejemplo. Un análisis visual de las dos gráficas anteriores nos permite crear el siguiente diccionario que va a servir de función de mapeado:
d = {"setosa": 1, "versicolor": 0, "virginica": 2}
Ahora ya podemos crear la matriz de confusión, pasando como valores reales mapeados:
confusion_matrix(iris.species.map(d), iris.cluster)
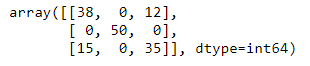
Y, para cuantificar el error, calculemos el accuracy_score:
from sklearn.metrics import accuracy_score
accuracy_score(iris.species.map(d), iris.cluster)
0.82