k-Means presupone que los clusters tienen forma convexa, lo que limita su eficacia en ciertos entornos. Por ejemplo, consideremos el dataset de las lunas:
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=400, noise=0.05, random_state=0)
Extraemos las características x e y:
x = X[:, 0]
y = X[:, 1]
...y las mostramos en un diagrama de dispersión:
sns.scatterplot(x, y, legend = False);
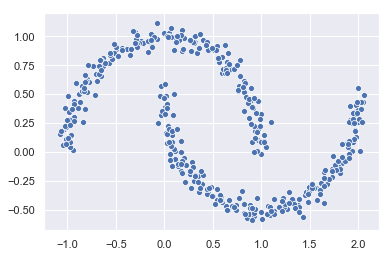
En este dataset, parecería obvio pensar que cada de las lunas supone un cluster independiente, pero no son formas convexas, lo que impide a k-Means reconocer adecuadamente los clusters. Por el contrario, impone su criterio de distancia para escogerlos.
Vamos a instanciar k-Means especificando 2 clusters, a entrenarlo y a generar la predicción:
from sklearn.cluster import KMeans
model = KMeans(n_clusters = 2, random_state = 0)
clusters = model.fit_predict(X)
Si visualizamos el resultado:
sns.scatterplot(x, y, hue = clusters);
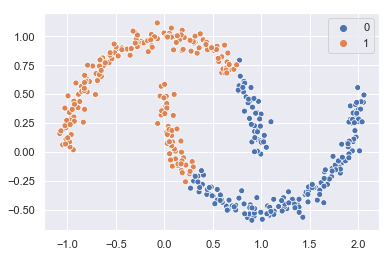
...confirmamos que el criterio ha sido por distancia, no por densidad de puntos.