Para ver este algoritmo en funcionamiento, vamos a generar datos aleatorios con la función make_blobs de Scikit-learn. Calculamos también los valores mínimos y máximos generados en ambas dimensiones (valores a los que añadimos un cierto margen para facilitar la generación de la gráfica asociada):
X, y = make_blobs(n_samples = [100, 250], random_state = 0, cluster_std = [0.5, 2.0], center_box = [(0, 0), (2, 2)])
minX = min(X[:, 0]) - 1
maxX = max(X[:, 0]) + 1
minY = min(X[:, 1]) - 1
maxY = max(X[:, 1]) + 1
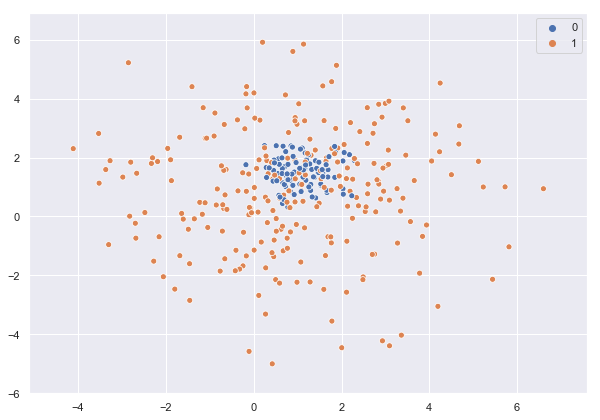
Veamos la distribución de los datos generados:
fig, ax = plt.subplots(figsize = (10, 7))
plt.axis([minX, maxX, minY, maxY])
sns.scatterplot(X[:, 0], X[:, 1], hue = y);
Ahora instanciamos la clase SVC con kernel "rbf" (valor por defecto):
model = SVC(gamma = "auto", kernel = "rbf")
model.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
Ya podemos realizar predicciones. Por ejemplo, el punto (0, 0):
sample = np.array([0, 0]).reshape(-1, 2)
model.predict(sample)
array([1])
...se asignaría a la clase 1 (naranja). Otro ejemplo:
sample = np.array([1, 2]).reshape(-1, 2)
model.predict(sample)
array([0])
El punto (1, 2) se asignaría a la clase 0 (azul).
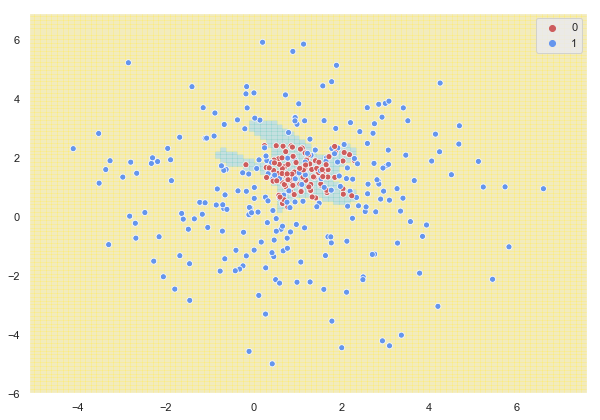
Si mostramos la distribución de las áreas a las que se asignaría cada clase obtenemos la siguiente gráfica (sobre la que se muestran los puntos del conjunto de entrenamiento):
def p(model, x, y):
sample = np.array([x, y]).reshape(-1, 2)
return model.predict(sample)[0]
pv = np.vectorize(p)
n = 100
ax = np.linspace(minX, maxX, n)
ay = np.linspace(minY, maxY, n)
xx, yy = np.meshgrid(ax, ay)
palette = ["IndianRed", "CornflowerBlue"]
zz = pv(model, xx, yy)
fig, ax = plt.subplots(figsize = (10, 7))
plt.pcolormesh(xx, yy, zz, cmap = plt.get_cmap('Set3'), alpha = 0.4);
sns.scatterplot(X[:, 0], X[:, 1], hue = y, palette = palette);
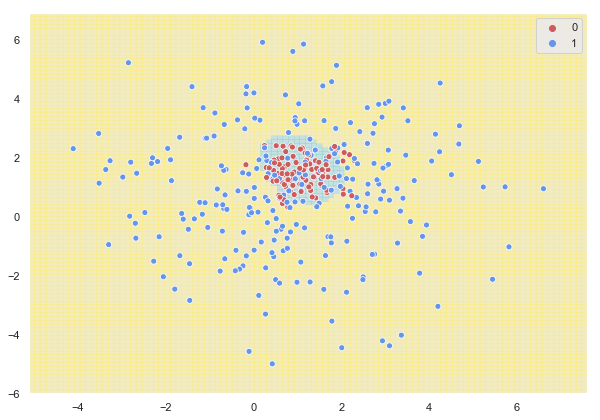
Si fijamos un valor de C alto (penalizando los errores en la clasificación), el resultado es el siguiente:
model = SVC(gamma = "auto", kernel = "rbf", C = 100000)
model.fit(X, y)
zz = pv(model, xx, yy)
fig, ax = plt.subplots(figsize = (10, 7))
plt.pcolormesh(xx, yy, zz, cmap = plt.get_cmap('Set3'), alpha = 0.4);
sns.scatterplot(X[:, 0], X[:, 1], hue = y, palette = palette);