Ya tenemos una cierta intuición acerca del significado del término entrenamiento: se trata del proceso por el que el algoritmo extrae de los datos la información necesaria para la construcción del modelo predictivo.
En el ejemplo de la aseguradora de coches que se comentó en la introducción de este tutorial, el objetivo del algoritmo era la construcción de un árbol de decisión que fuese clasificando los registros de datos conocidos (los tomadores de seguros) de forma que, una vez terminado, pudiésemos aplicarlo a nuevos registros (a potenciales tomadores de seguros) haciéndolos pasar por el árbol comenzando por la parte superior y respondiendo todas las preguntas hasta llegar a un nodo final (a lo que llamamos "una hoja" del árbol), nodo en el que encontraríamos la probabilidad de accidente:.
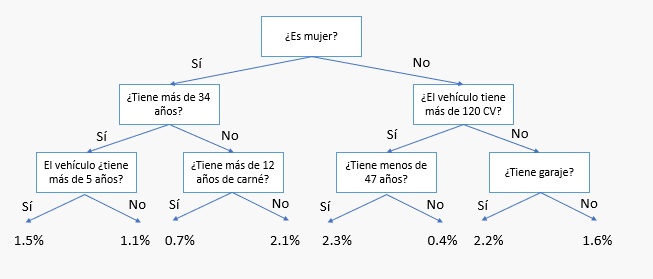
La pregunta que podríamos hacernos al respecto de dicho árbol es "¿Conviene que el árbol no sea muy profundo? (es decir, que no haya que responder muchas preguntas antes de llegar al final) ¿o que, por el contrario, tenga la máxima profundidad posible?"
A primera vista, un árbol de solo tres niveles (como el mostrado en la figura anterior) no está clasificando a los posibles conductores más que según tres variables (las que definen las preguntas que se responden en cada nodo), de forma que estaríamos clasificando a los conductores en solo unos pocos grupos (cuatro, concretamente), corriendo el riesgo de estar considerando de forma semejante a perfiles de tomadores muy distintos. Entonces, ¿por qué no crear el árbol con la mayor profundidad que sea posible para tener a todos los conductores del conjunto de entrenamiento perfectamente clasificados?