Un árbol de decisión, tal y como su nombre sugiere, crea, a partir de los datos de entrenamiento, una estructura en forma de árbol en la que, en cada nodo, va dividiendo los datos de forma que los bloques resultantes de cada división sean más "puros" que el bloque original.

Por ejemplo, supongamos que partimos de un dataset conteniendo dos características predictivas, x1 y x2, y que cada muestra pertenece a una de dos posibles clases:
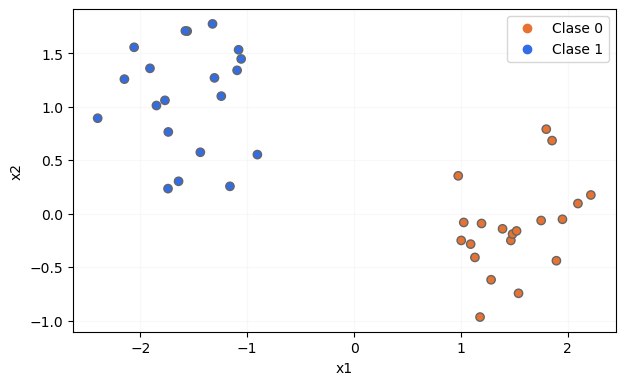
Aunque se concretará el término "pureza" en breve, partamos de la idea de que este concepto hace referencia a la homogeneidad de un grupo de datos, de forma tal que, si en un grupo hay una clase dominante (si la mayor parte de las muestras pertenecen a una misma clase), se dice que tiene una pureza alta, mientras que si contiene elementos de varias clases y no hay una clase dominante, se dice que su pureza es baja. En los extremos, un grupo tiene la mayor pureza posible cuando solo contiene muestras de una clase, y tiene la menor pureza posible cuando contiene muestras de varias clases y el número de muestras de cada clase es el mismo.
Según este criterio, parece razonable pensar que el dataset del que partimos, al contener muestras de las dos clases, va a tener una pureza baja. Pues bien, el objetivo del árbol de decisión es dividir los datos según algún criterio, de forma que los bloques resultantes de la división supongan una mayor pureza que la del dataset original.
A continuación, el algoritmo va a intentar dividir cada uno de los bloques obtenidos según algún otro criterio con el mismo objetivo de aumentar la pureza de los bloques resultantes, y este proceso va a continuar hasta que la pureza de los bloques sea la máxima posible.