En el ejemplo comentado partimos de un dataset que contiene dos características predictivas, de forma que podríamos basarnos en cualquiera de ellas para dividir nuestros datos. Por ejemplo, podríamos dividir el dataset de forma que, en un bloque, se incluyeran las muestras en las que la característica x1 tomase un valor inferior o igual a -1.5. Esto supondría dividir las muestras en los siguientes dos bloques:
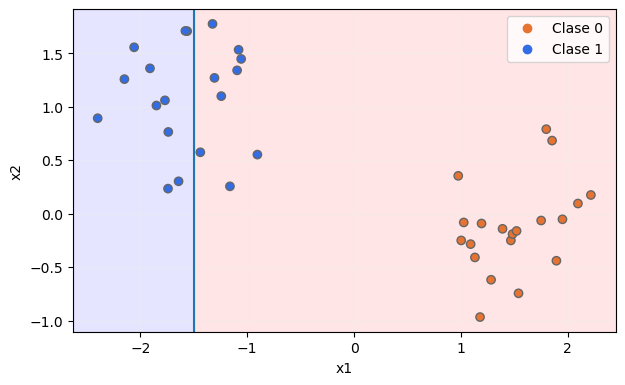
El bloque de la izquierda (con fondo azulado) solo contendría muestras de la clase 1, por lo que su pureza sería máxima, pero el bloque de la derecha (con fondo rojizo) contendría muestras de las dos clases, por lo que su pureza sería baja.
Otra posibilidad sería dividir el dataset original de forma que, en el primer bloque, se incluyesen todas las muestras en las que la característica x2 tomase un valor mayor o igual a 0.5, lo que supondría la creación de los siguientes dos bloques:
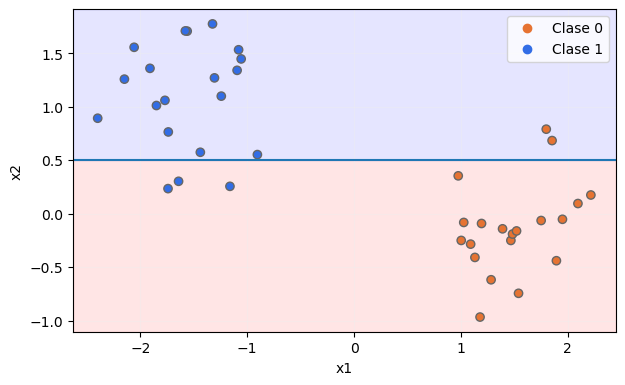
En este segundo caso, el bloque superior (con fondo azulado) contendría una clase dominante (la clase 1) pero su pureza no sería máxima, pues incluye también dos muestras de la clase 0. Y el bloque inferior (con fondo rojizo) también contendría una clase dominante (la clase 0) pero su pureza tampoco sería máxima, pues incluye tres muestras de la clase 1.
Parece bastante obvio que, con estos datos, la división o "split" ideal sería dividir los datos según la característica x1 de forma que las muestras en las que dicha característica tome el valor 0 o inferior se incluyan en uno de los bloques, y las muestras en la que esta característica tome un valor superior a 0 se incluyan en el segundo bloque:
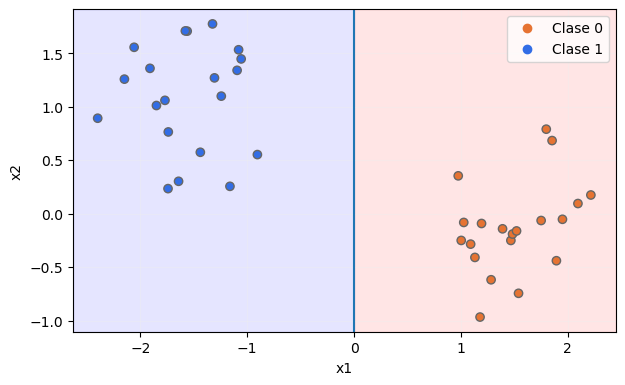
Ahora, tanto el bloque de la izquierda como el bloque de la derecha solo contienen muestras de una clase, por lo que su pureza es máxima.
Hemos escogido como valor de la división el umbral x1 = 0, pero puede verse que cualquier valor próximo a 0 también hubiese servido.
Y, por supuesto, esto se realiza bajo la hipótesis de que futuras muestras cuya clase queramos predecir van a mantener un comportamiento semejante al de los datos que conocemos. Esto es, que las muestras de la clase 0 tenderán a caracterizarse por tener un valor en la característica x1 superior a 0, y que las muestras de la clase 1 tenderán a caracterizarse por tener un valor en la característica x1 inferior o igual a 0.