Es decir, el algoritmo ha creado el siguiente árbol de decisión a partir de los datos:
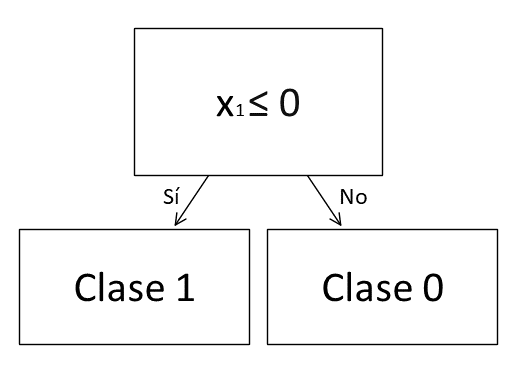
Para determinar la clase de una muestra -para realizar una predicción- debemos comenzar por el nodo superior respondiendo la pregunta que se realiza en él: ¿el valor de la característica predictiva x1 es menor o igual a 0? En caso positivo, la clase asignada es la 1 y, en caso negativo, la clase asignada es la 0.
En este ejemplo, nuestro árbol de decisión es de profundidad 1, lo que implica que solo se divide el dataset según un criterio. Los nodos que se muestran en la parte inferior del árbol y que nos indican la clase asignada se denominan hojas.