Probemos el clasificador basado en árbol de decisión de Scikit-Learn con el dataset Iris:
iris["label"] = iris.species.astype("category").cat.codes
Téngase en cuenta que la implementación del árbol de decisión de Scikit-Learn permite su entrenamiento usando como etiquetas valores no numéricos. En nuestro caso estamos codificando la especie para poder mostrar las fronteras de decisión. Y por este mismo motivo vamos a entrenarlo solo con dos características predictivas, tal y como hemos hecho en secciones anteriores:
y = iris.label
Importamos la clase DecisionTreeClassifier, la instanciamos y entrenamos el modelo:
model.fit(X.values, y)
Visualicemos las fronteras de decisión:
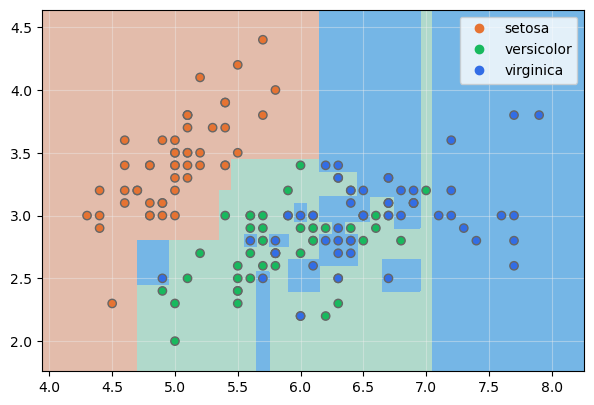
El algoritmo claramente ha sido sobreentrenado. Podemos visualizar el árbol usando la función plot_tree() que se encuentra en la misma librería:
plot_tree(model, filled = True, feature_names = X.columns)
plt.show()
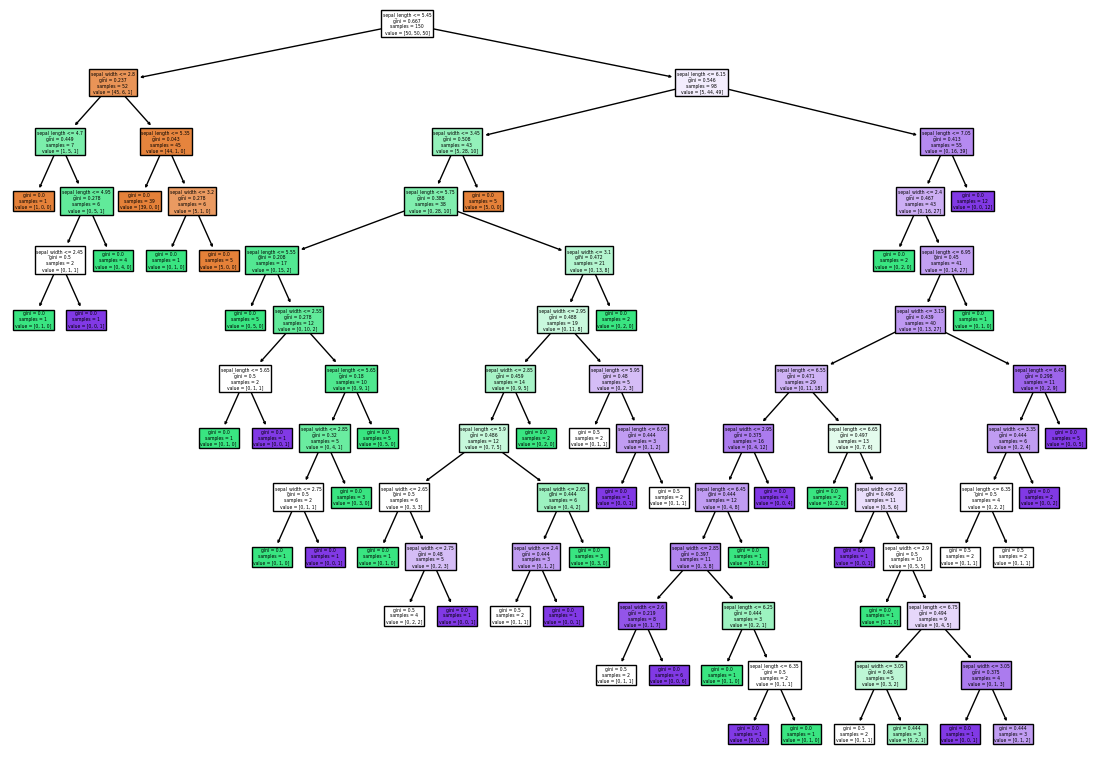
Efectivamente, podemos ver que el árbol ha crecido sin límite. En la práctica lo ha hecho hasta que ha clasificado correctamente todas las muestras.