Si queremos obtener la predicción para una muestra (o para un conjunto de ellas), no tenemos más que recurrir al método .predict(). Por ejemplo, visualicemos la muestra que ocupa el índice 2 del dataset de validación:

La predicción del modelo es:
Según nuestro modelo, esta muestra pertenece a la clase 1 ¿Y cuál es la probabilidad asociada a esta predicción? Para ello tenemos a nuestra disposición el método .predict_proba():
Según el modelo, hay una probabilidad del 0% de que la muestra pertenezca a la clase 0, un 64.51% de que pertenezca a la clase 1, y un 35.48% de que pertenezca a la clase 2.
Lo cierto es que esta información es fácilmente obtenible a partir del árbol:
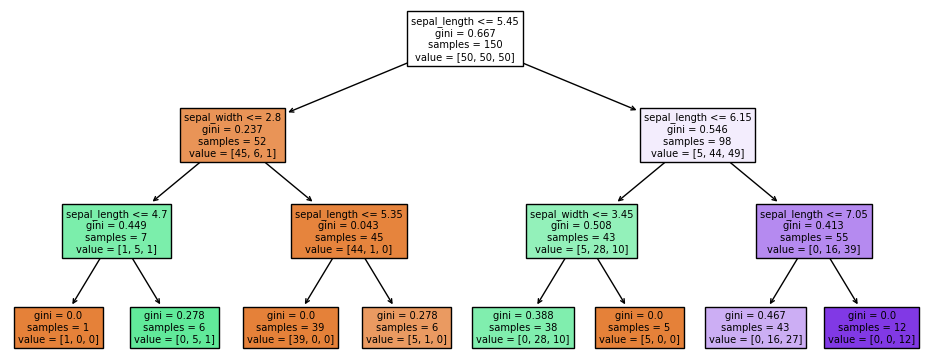
Nuestra muestra tiene una longitud de sépalo de 5.8, por lo que no cumple la primera condición y es agrupada en el bloque de la derecha. Sí cumple la condición planteada por este segundo nodo, por lo que se agrupa en el bloque de la izquierda (en verde). Por último, en este nodo se plantea si el ancho del sépalo es o no menor o igual a 3.45, condición que nuestra muestra sí cumple, por lo que va a caer en la hoja de la izquierda (también en verde). En esta hoja se incluyeron 0 muestras de la clase 0, 28 de la clase 1 y 10 de la clase 2, por lo que, al ser la clase 1 dominante, cualquier muestra que llegue a esta hoja recibirá esta clasificación.
Por último, en esta hoja hay 38 muestras de las que 0 son de clase 0, por lo que la probabilidad estimada de que lleguen a esta hoja muestras de dicha clase es de 0/38 = 0%. De la clase 1 hemos dicho que hay 28, por lo que la probabilidad asignada a esta clase es de 28/38 = 64.51%. Y de la clase 2 hay 10 muestras, por lo que la probabilidad asignada a esta clase es de 10/38 = 35.48%.