Podemos comprobar fácilmente cuál es el efecto que tiene el fijar una profundidad máxima en el conjunto de datos de entrenamiento y en el de validación: basta con entrenar varios modelos con profundidades máximas entre 1 y, por ejemplo, 15, y visualizar el porcentaje de acierto en cada caso.
Comenzamos dividiendo el dataset en dos bloques:
Ahora entrenamos los 15 modelos (recordemos que la función range devuelve un generador de números que no incluye el extremo derecho del rango):
test_scores = []
for depth in range(1, 16):
model = DecisionTreeClassifier(max_depth = depth)
model.fit(X_train, y_train)
train_scores.append(model.score(X_train, y_train))
test_scores.append(model.score(X_test, y_test))
Visualicemos ahora el resultado:
ax.plot(range(1, 16), train_scores, label = "Train dataset")
ax.plot(range(1, 16), test_scores, label = "Test dataset")
ax.set_xticks(range(1, 16), labels = range(1, 16))
ax.grid(color = "#EEEEEE", zorder = 0)
ax.set_ylim(0, 1)
ax.legend()
plt.show()
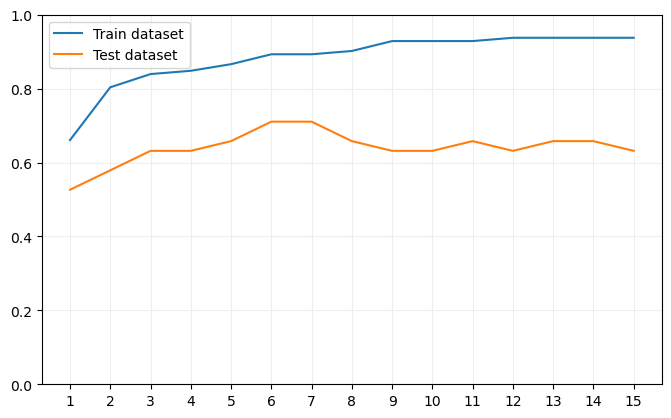
Comprobamos que, a medida que aumenta la profundidad máxima, aumenta el porcentaje de aciertos tanto en el dataset de entrenamiento como en el de pruebas, pero llega un momento (con los árboles de profundidad máxima 6 y 7) en el que el resultado en el dataset de pruebas toca un máximo y comienza a decrecer, características típicas de lo que denominamos sobreentrenamiento.