El escalador sklearn.preprocessing.MinMaxScaler transforma las características escalándolas a un rango dado, por defecto (0,1), aunque puede ser personalizado. Este tipo de escalado suele denominarse frecuentemente "escalado" de los datos.
Veamos un ejemplo sencillo. Supongamos que partimos de los siguientes datos:
data
[ 4],
[ -1],
[-60]])
Importemos e instanciemos el escalador, y apliquémoslo al array:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit_transform(data)
[0.98461538],
[0.90769231],
[0. ]])
Vemos que el valor máximo del resultado es 1 y el mínimo es 0.
Apliquémoslo ahora al dataset Iris:
iris = sns.load_dataset("iris")
iris.head()
Ahora importamos e instanciamos la clase con las opciones por defecto:
Solo estamos interesados en escalar las características predictivas (no es necesario escalar la variable objetivo), de forma que entrenamos el escalador y transformamos las primeras cuatro columnas del dataframe:
transformed_iris = scaler.fit_transform(iris.iloc[:, :4])
Considerando que el resultado devuelto por el escalador es un array bidimiensional, a continuación podemos reconstruir el DataFrame, añadiendo al array en cuestión la columna "species" con la variable objetivo y dando nombre a todas las columnas:
transformed_iris = pd.DataFrame(transformed_iris)
transformed_iris["species"] = iris["species"]
transformed_iris.columns = iris.columns
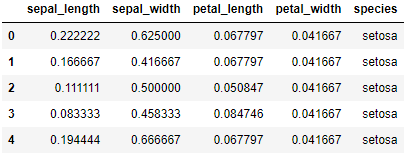
Veamos el resultado:
transformed_iris.head()
Podemos confirmar la distribución de las características con el método describe, que ofrece información estadística del DataFrame:
transformed_iris.describe()
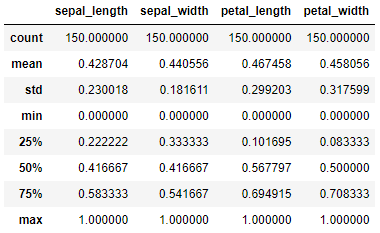
Vemos que los valores máximos y mínimos son 1.0 y 0.0 respectivamente.