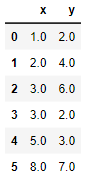
La clase sklearn.preprocessing.StandardScaler estándariza los datos eliminando la media y escalando los datos de forma que su varianza sea igual a 1. Este tipo de escalado suele denominarse frecuentemente "normalización" de los datos. Veamos un ejemplo. Partimos del siguiente conjunto de datos:
x = [1, 2, 3, 3, 5, 8]
y = [2, 4, 6, 2, 3, 7]
data = pd.DataFrame({"x": x, "y": y}, dtype = "float64")
data
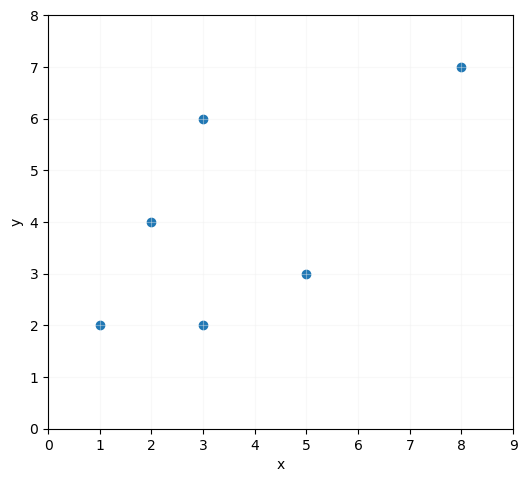
Mostrémoslos en una gráfica y calculemos el valor medio y varianza de las características:
ax.set_aspect("equal")
ax.scatter(x = x, y = y)
ax.grid(color = "#EEEEEE", zorder = 1, alpha = 0.4)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_xlim(0, 9)
ax.set_ylim(0, 8)
plt.show()
print(np.mean(data.x))
print(np.mean(data.y))
4.0
print(np.var(data.x))
print(np.var(data.y))
3.6666666666666665
Ahora vamos a importar el escalador, instanciarlo y, a continuación, entrenarlo y transformar el dataframe:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data_transformed = scaler.fit_transform(data)
data_transformed

Los valores mostrados son los equivalentes a los iniciales una vez transformados. Tal y como se puede ver, el escalador devuelve un array NumPy, no un DataFrame Pandas. Comprobemos los valores medios y las varianzas de estas características transformadas (extraemos las columnas para mayor comodidad):
y_transformed = data_transformed[:, 1]
print(np.mean(y_transformed))
0.0
print(np.var(y_transformed))
1.0
Ahora los valores medios son nulos (la cifra que vemos de 1.11e-16 es debido al redondeo) y las varianzas iguales a 1. Si mostramos los puntos en una gráfica obtenemos el siguiente resultado:
ax.set_aspect("equal")
ax.scatter(x = x_transformed, y = y_transformed)
ax.grid(color = "#EEEEEE", zorder = 1, alpha = 0.4)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_xlim(-2, 2.5)
ax.set_ylim(-2, 2)
plt.show()
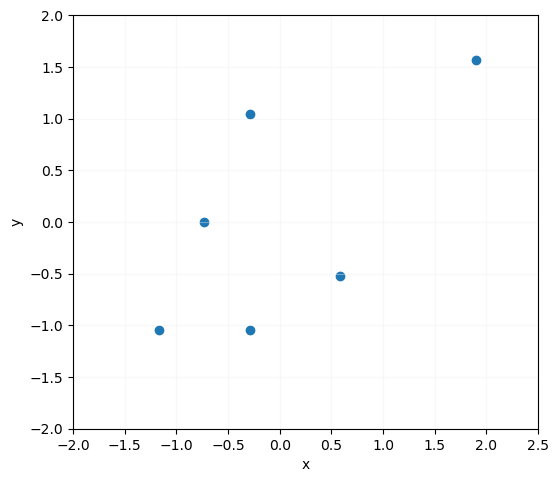
Comprobamos que, salvo el escalado y el desplazamiento, la distribución de los datos es exactamente la original.