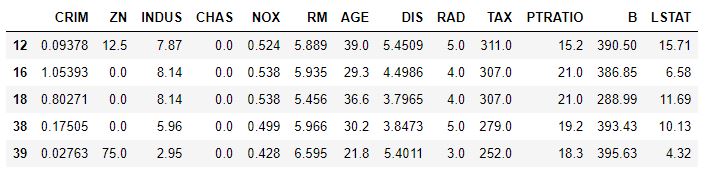
Comencemos trabajando con una única variable predictiva: el número medio de habitaciones. Cargamos el dataset y seleccionamos solo las viviendas cuya edad sea inferior a 40 años (para poder trabajar con un conjunto de datos menor y visualizarlo más cómodamente). Dividimos el dataset en variables predictivas (X, inicialmente todas) y variable objetivo (y):
df = load_boston()
X = pd.DataFrame(df.data, columns = df.feature_names)
X["target"] = df.target
X = X[X.AGE < 40]
y = X.pop("target")
X.head()
Visualicemos la relación entre el número medio de habitaciones (característica RM) y el precio medio (variable objetivo):
sns.scatterplot(X.RM, y);
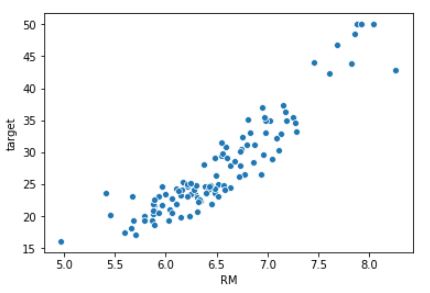
La relación parece bastante clara. Aproximemos la variable objetivo mediante un algoritmo de regresión lineal. Comencemos separando del dataset un conjunto de muestras para probar el resultado:
X = X[["RM"]]
y = y.values.reshape(-1, 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.10, random_state = 1)
A continuación, instanciamos el algoritmo y lo entrenamos:
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
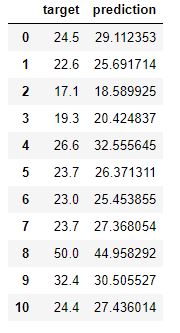
Calculamos la predicción y la mostramos junto a la variable objetivo:
prediction = model.predict(X_test)
pd.DataFrame({"target": y_test.ravel(), "prediction": prediction.ravel()}, index = range(len(y_test)))
Por último, podemos evaluar el modelo ejecutando el método score(), que devuelve el coeficiente R2:
model.score(X_test, y_test)