seaborn incluye un interesante conjunto de datasets que pueden ser utilizados para probar las distintas visualizaciones. La función disponible para la carga de estos conjuntos de datos es seaborn.load_dataset, devolviendo un dataframe pandas. A lo largo de este tutorial se utilizarán algunos de estos datasets:
flights
flights = sns.load_dataset("flights")
flights.sample(5)
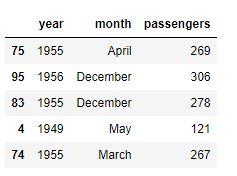
Dataset con información sobre pasajeros transportados en avión por mes entre 1949 y 1960. Las cifras de pasajeros probablemente hacen referencia a "miles" de pasajeros (no está documentado).
titanic
titanic = sns.load_dataset("titanic")
titanic.sample(5)
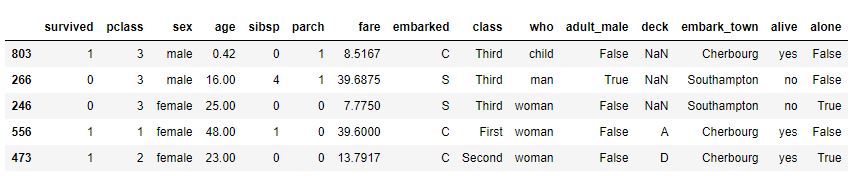
Famoso conjunto de datos con información sobre los pasajeros del último viaje del Titanic, con información sobre quiénes sobrevivieron, su edad, sexo, clase en la que viajaban...
iris
iris = sns.load_dataset("iris")
iris.sample(5)
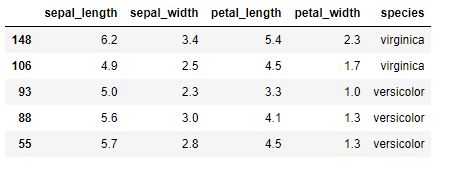
Otro de los clásicos, con información de la longitud y ancho de pétalos y sépalos de 150 flores Iris de tres especies relacionadas.
tips
tips = sns.load_dataset("tips")
tips.sample(5)
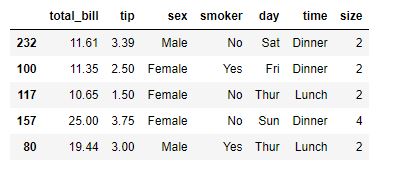
En este conjunto de datos hay información sobre propinas dejadas en un restaurante, con información sobre el día en el que se produjo, si fue en el almuerzo o la cena, el número de comensales, el sexo de la persona que dejó la propina, si era fumador o no...
En este enlace puedes descargar los ficheros en formato CSV contenidos en todos los datasets de seaborn.