La librería seaborn se muestra especialmente útil en proyectos de análisis, y ya hemos visto las ventajas que tiene. Una de ellas es su integración con pandas: a la hora de visualizar los datos contenidos en un dataframe no es preciso extraer las características a visualizar, basta con indicar los nombres de las características y el nombre del dataframe en argumentos diferentes.
Por ejemplo, si estamos trabajando con el dataset del Titanic:
titanic = sns.load_dataset("titanic")
titanic.head(1)

...en matplotlib mostraríamos un gráfico de dispersión entre las características age y fare del dataframe de la siguiente forma:
import matplotlib.pyplot as plt
plt.scatter(titanic.age, titanic.fare, s = 6);
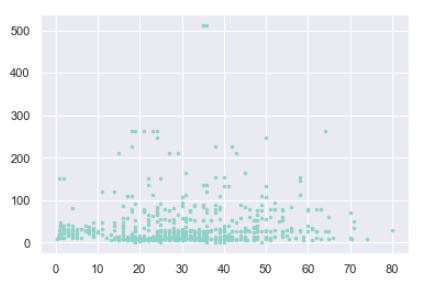
En seaborn, lo haríamos así:
sns.scatterplot("age", "fare", data = titanic);
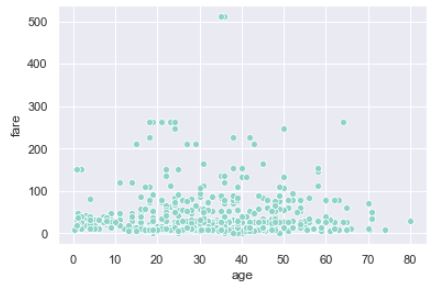
La diferencia no es excesiva, pero en ciertos escenarios puede resultar mucho más cómodo trabajar directamente con el dataframe que tener que extraer las características y, en ocasiones, adaptarlas al formato adecuado.
Esta ventaja, sin embargo, puede suponer una complicación, pues no siempre que queremos visualizar un conjunto de datos los tenemos organizados en un dataframe. A veces se trata de un simple array NumPy cuya distribución queremos conocer, o de dos características de cualquier otro tipo cuya estructura queremos analizar. La creación de un dataframe no es que sea algo especialmente pesado. Si tenemos dos campos x e y conteniendo datos a analizar, podríamos crear un dataframe así:
df = pd.DataFrame({"x":x, "y":y})
Simplemente resulta incómodo tener que realizar este paso previo antes de poder utilizar una función de visualización de seaborn.
Afortunadamente, no todas las funciones de seaborn exigen el uso de este esquema. Algunas (de hecho, la mayoría) permiten utilizar arrays o estructuras semejantes (listas o series pandas, por ejemplo) en lugar de referencias a características en un dataframe. Hagamos un repaso del tipo de datos de entrada que exigen las diferentes funciones disponibles.