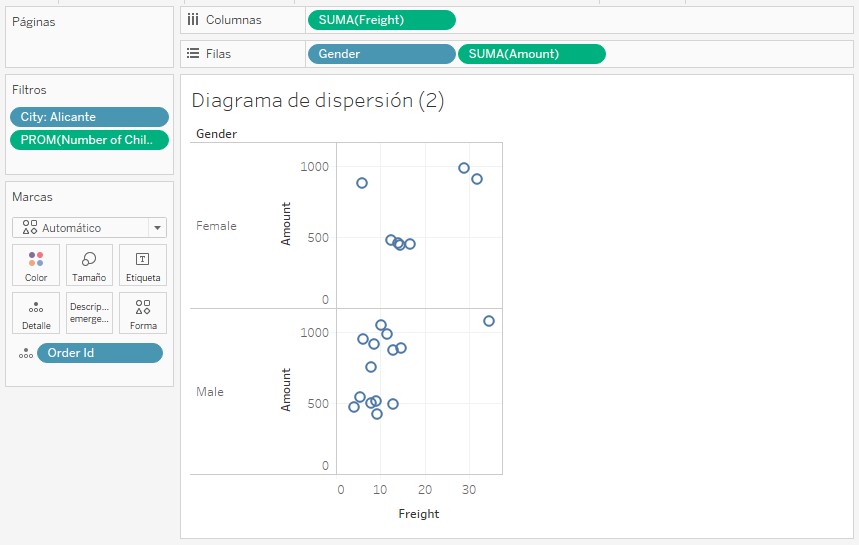
Para ver cómo funciona esta línea, partimos de un diagrama de dispersión semejante al anterior, segmentado según el género del cliente, y tras filtrarlo de forma que el número de ventas involucradas sea pequeño y los dos diagramas muestren de esta forma diferencias significativas:
Ahora llevamos la línea de promedio al lienzo:
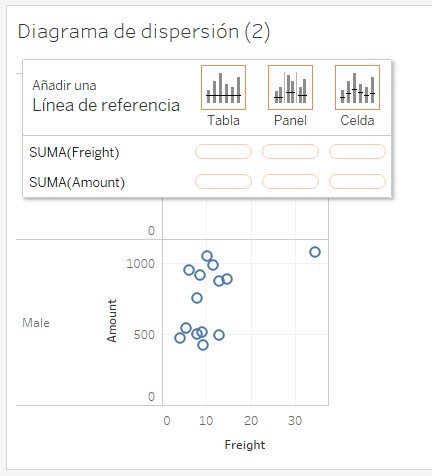
A diferencia de lo que veíamos en la línea de constante, ahora tenemos tres bloques de receptores para nuestra línea: tres para el tipo tabla (en rojo en la siguiente imagen), tres para el tipo panel (en verde) y tres para el tipo celda (en azul):

Ya sabemos que las tres opciones correspondientes a la tabla (en rojo) van a considerar los datos de toda la tabla subyacente a las gráficas. Esto significa que, si llevamos una línea de promedio a uno de estos receptores, el valor de dicha línea (o de dichas líneas) va a ser el mismo en los dos diagramas de dispersión. Y como vimos en la línea de constante, el receptor superior va a considerar todos los campos (es decir, creará dos líneas, una para el campo Freight y otra para el campo Amount), el siguiente considerará solo el campo Freight, y el último solo el campo Amount. Llevemos, por ejemplo, nuestra línea al receptor superior de este primer bloque de tabla:
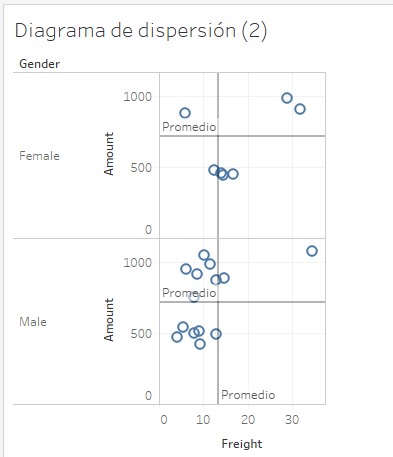
Se crean dos líneas (una para cada campo) en cada diagrama de dispersión, y las coordenadas de estas líneas son las mismas en ambos.
Si deshacemos este último paso, volvemos a crear la línea de promedio, pero esta vez la llevamos al receptor superior del bloque correspondiente al panel (en verde en la imagen que vimos), las líneas considerarán no todos los datos, sino solo los que afectan a cada panel:
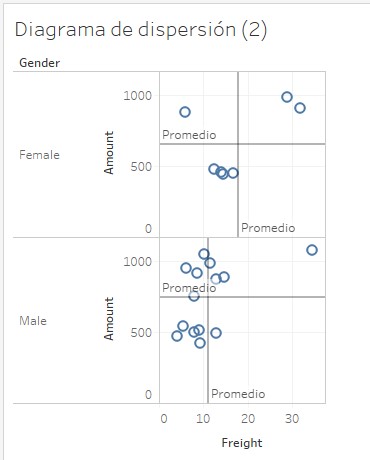
Por último, el bloque correspondiente a la celda (en azul) crearía las líneas basándose en los datos que alimentasen cada celda de la matriz de gráficas (que no existen en nuestro ejemplo).