El método pandas.DataFrame.reindex ofrece una funcionalidad semejante a la disponible para series con la particularidad de que, en este caso, podemos reindexar por filas y/o por columnas. Por defecto, este método acepta una secuencia de etiquetas que determinarán qué filas se incluyen y en qué orden (es decir, por defecto la reindexación se aplica al eje 0):
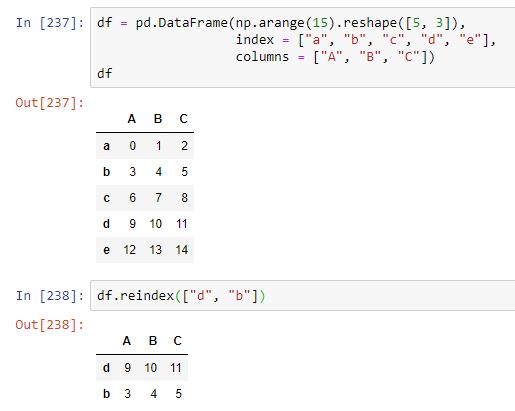
En este ejemplo, partimos de un dataframe cuyo índice de filas tiene las etiquetas "a", "b", "c", "d" y "e", y hemos indicado como nuevo índice apenas las etiquetas "d" y "b" (en este orden), y son estas filas (en ese orden) las que se devuelven como resultado.
Este método permite especificar las etiquetas de filas como hemos visto, pasándoselas al método como primer argumento, o con el parámetro index:
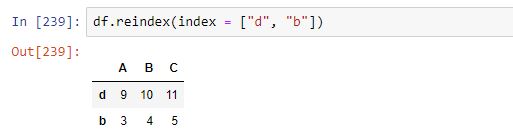
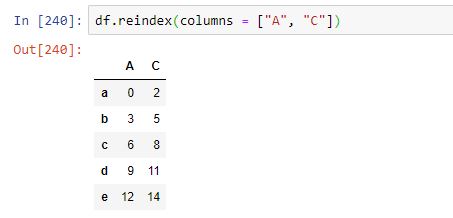
El resultado, por supuesto, es el mismo. El parámetro columns, por su parte, permite especificar el nuevo índice de columnas:
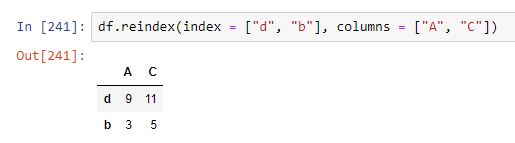
Si utilizamos ambos parámetros al mismo tiempo, imponemos simultáneamente el nuevo índice para filas y columnas:
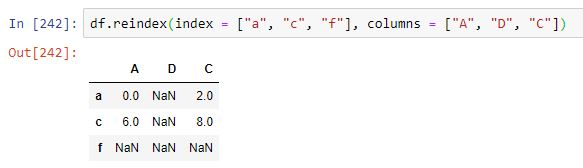
La gestión de etiquetas que no existan en los índices iniciales es la misma que la vista para las series: se añaden y se les asigna el valor NaN:
Podemos asignar a los valores inexistentes un valor concreto usando el parámetro fill_value, o podemos aplicar "lógica de relleno" con el parámetro method, permitiéndonos rellenar los valores inexistentes hacia adelante o hacia atrás.
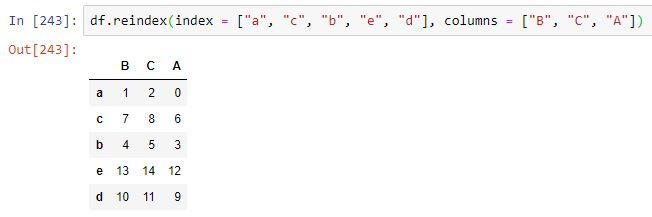
Y, por supuesto, si los nuevos índices contienen los mismos elementos que los índices originales pero en otro orden, el resultado del método será equivalente al original ordenado según el nuevo criterio: