pandas.crosstab(
index,
columns,
values = None,
rownames = None,
colnames = None,
aggfunc = None,
margins = False,
margins_name = 'All',
dropna = True,
normalize = False
)
La función pandas.crosstab devuelve la tabla de contingencia resultante de cruzar dos o más campos de un dataframe. Aunque, por defecto, el resultado evalúa las frecuencias (absolutas o relativas) de cada combinación de valores, es posible especificar una función de agregación.
- index: Variable tipo array, serie pandas o lista de arrays/series, valores según los cuales desagregar las filas.
- columns: Variable tipo array, serie pandas o lista de arrays/series, valores según los cuales desagregar las columnas.
- values: Valores a los que aplicar las funciones de agregación indicadas por el parámetro aggfunc.
- rownames: Secuencia. Nombres a dar a los niveles del índice de filas del resultado.
- colnames: Secuencia. Nombres a dar a los niveles del índice de columnas del resultado.
- aggfunc: Función o secuencia de funciones. Funciones de agregación a aplicar a los valores dados por el parámetro values para cada combinación de filas y columnas identificada.
- margins: Booleano. Si toma el valor True, la tabla resultante incluirá subtotales.
- margins_name: String. Nombre a dar a la fila o columna que contendrá los subtotales. Por defecto se aplica el nombre "All".
- dropna: Booleano. Si toma el valor True, el resultado no considerará las columnas cuyos valores sean todos NaN.
- normalize: Booleano, string o número entero. En función del valor que tome este parámetro, en lugar de una tabla de frecuencias absolutas, el resultado incluirá una tabla de frecuencias relativas calculadas con respecto al total, al subtotal de filas o al subtotal de columnas. Concretamente:
- Si este parámetro toma el valor "all" o True, la normalización se realizará con respecto al número total de muestras.
- Si toma el valor "index" o 0, la normalización se realizará con respecto al subtotal correspondiente a cada fila.
- Si toma el valor "columns" o 1, la normalización se realizará con respecto al subtotal correspondiente a cada columna.
- Si toma el valor False (valor por defecto), el resultado de la función no se normalizará.
La función pandas.crosstab devuelve un dataframe pandas.
Partamos del dataset tips proveído por la librería seaborn:
import pandas as pd
import seaborn as sns
tips = sns.load_dataset("tips")
tips.head()

Este dataset incluye 244 muestras:
tips.shape
(244, 7)
Podríamos averiguar el reparto de muestras resultante de cruzar los campos "sex" y "smoker" con la siguiente instrucción:
pd.crosstab(tips.sex, tips.smoker)

Observamos que las 244 muestras se reparten de la siguiente forma:
- 60 hombres fumadores
- 97 hombres no fumadores
- 33 mujeres fumadoras
- 54 mujeres no fumadoras
crosstab & groupby
Obsérvese que podríamos haber obtenido el mismo resultado aplicando la función pandas.DataFrame.groupby. Comenzamos agrupando la tabla tips según los valores de los campos "sex" y "smoker" y aplicando la función count como función de agregación:
tips.groupby(["sex", "smoker"])["tip"].count()
sex smoker
Male Yes 60
No 97
Female Yes 33
No 54
Name: tip, dtype: int64
...y aplicamos el método pandas.DataFrame.unstack:
tips.groupby(["sex", "smoker"])["tip"].count().unstack()
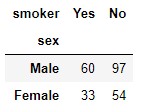
crosstab & pivot_table
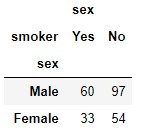
También podríamos haber obtenido el mismo resultado usando la función pandas.DataFrame.pivot_table (funcionalidad (también disponible como método), aplicando como función de agregación la "longitud" del bloque de datos correspondiente a uno de los dos campos involucrados:
tips.pivot_table(index = "sex", columns = "smoker", aggfunc = {"sex": len})
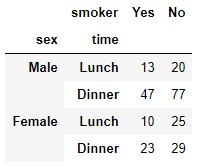
La desagregación de filas y columnas puede realizarse según más de una variable. Por ejemplo:
pd.crosstab([tips.sex, tips.time], tips.smoker)
Parámetros margins y margins_name
El uso del parámetro margins nos permite añadir subtotales de filas y columnas (no es posible mostrar subtotales solo en una única dimensión):
pd.crosstab(tips.sex, tips.smoker, margins = True)
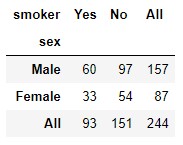
El nombre de la fila/columna con el subtotal puede configurarse usando el parámetro margins_name:
pd.crosstab(tips.sex, tips.smoker, margins = True, margins_name = "subtotal")

Parámetro normalize
En lugar de mostrar las frecuencias absolutas de cada combinación, podemos "normalizar" dichas frecuencias con respecto al total o con respecto a los subtotales de filas o columnas. Por ejemplo, si asignamos al parámetro normalize el valor True, la normalización se realiza con respecto al total de muestras:
pd.crosstab(tips.sex, tips.smoker, normalize = True)
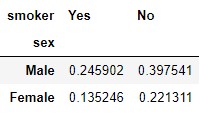
En el resultado anterior comprobamos que, redondeando, el 24.5% de las muestras corresponden a hombres fumadores, el 39.7% a hombres no fumadores, el 13.5% a mujeres fumadoras, y el 22.1% a mujeres no fumadoras. Por supuesto, la suma de estos cuatro porcentajes es 100%.
Si queremos que la normalización se realice según el subtotal de filas -por ejemplo-, podríamos conseguirlo con el siguiente código:
pd.crosstab(tips.sex, tips.smoker, normalize = "index")

En este resultado vemos que el 100% de los hombres se divide en un 38.2% que fuma y en un 61.7% que no fuma. Y que el 100% de las mujeres se divide en un 37.9% que fuma y en un 62.0% que no lo hace.
Parámetros rownames y colnames
Estos parámetros se utilizan para dar nombres a los índices. Por ejemplo, si estamos cruzando los campos "sex" y "smoker" como en los ejemplos anteriores, los índices de filas y columnas reciben esos mismos nombres:
pd.crosstab(tips.sex, tips.smoker)
Pero podríamos cambiarlos usando los parámetros en cuestión:
pd.crosstab(
tips.sex,
tips.smoker,
rownames = ["Sexo"],
colnames = ["Fumador"]
)

Si estuviésemos cruzando más de dos campos (incluyendo el resultado un índice multinivel), el número de nombre deberá coincidir con el número de niveles de cada índice. Por ejemplo:
pd.crosstab(
[tips.sex, tips.time],
tips.smoker,
rownames = ["Sexo", "Tipo"],
colnames = ["Fumador"]
)

Parámetros aggfunc y values
Todos los ejemplos vistos hasta ahora desagregaban los campos que se llevaban a filas y columnas y se contabilizaba su frecuencia (absoluta o relativa). Pongamos un ejemplo muy simple: llevemos a la variable t un conjunto de 8 muestras aleatorias extraídas del dataset tips:
t = tips.sample(8, random_state = 0)
t
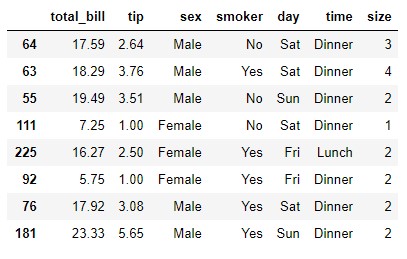
Obtengamos ahora la tabla de contingencia cruzando los campos sex y smoker:
pd.crosstab(t.sex, t.smoker)

Ya sabemos que lo que estamos haciendo es agrupar las muestras según el criterio definido por la combinación de los valores de los dos campos. Por ejemplo, en el resultado anterior vemos que hay tres hombre fumadores, dos hombres no fumadores, dos mujeres fumadoras y una mujer no fumadora.
Sin embargo, una vez desagregados nuestros datos en estos cuatro bloques, podríamos estar interesados en aplicar una o más funciones de agregación a campos adicionales del dataset. Por ejemplo, podríamos querer calcular el valor medio de las propinas (campo tip) para estos bloques de clientes.
Pues bien, esto es exactamente lo que nos permiten los parámetros aggfunc y values: el primero nos permite indicar la función o funciones de agregación a aplicar y, el segundo, los datos a los que aplicarlos. El valor medio de las propinas mencionado podría obtenerse con el siguiente código:
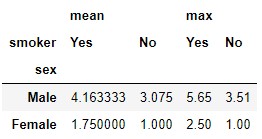
pd.crosstab(t.sex, t.smoker, aggfunc = "mean", values = t.tip)

Confirmemos que el cálculo es correcto: vimos que hay tres hombres fumadores. Si revisamos el dataset t vemos que las propinas dejadas por estos clientes toman los valores 3.76, 3.08 y 5.65:
t.loc[(t.sex == "Male") & (t.smoker == "Yes")]
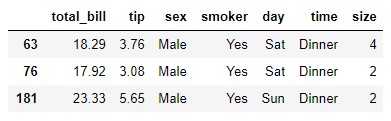
El valor medio de estos tres valores es 4.1633, que es el valor que aparece como resultado de nuestra tabla de contingencia.
Podemos aplicar más de una función de agregación. Por ejemplo, podríamos estar interesados en el valor medio y en el valor máximo de las propinas para cada uno de esos cuatro grupos de clientes:
pd.crosstab(t.sex, t.smoker, aggfunc = ["mean", "max"], values = t.tip)